
Những quyết định mạng máy tính "ngược đời" giúp OpenAI vận hành 131.000 GPU
Giao thức MRC mới do OpenAI và các đối tác phát triển đã đảo ngược ba thập kỷ quan điểm về thiết kế mạng trung tâm dữ liệu bằng cách loại bỏ định tuyến động và chấp nhận mất gói tin. Hệ thống này cho phép kết nối 131.000 GPU với độ trễ cực thấp và khả năng phục hồi lỗi vượt trội, tối ưu hóa cho việc huấn luyện các mô hình AI quy mô lớn.
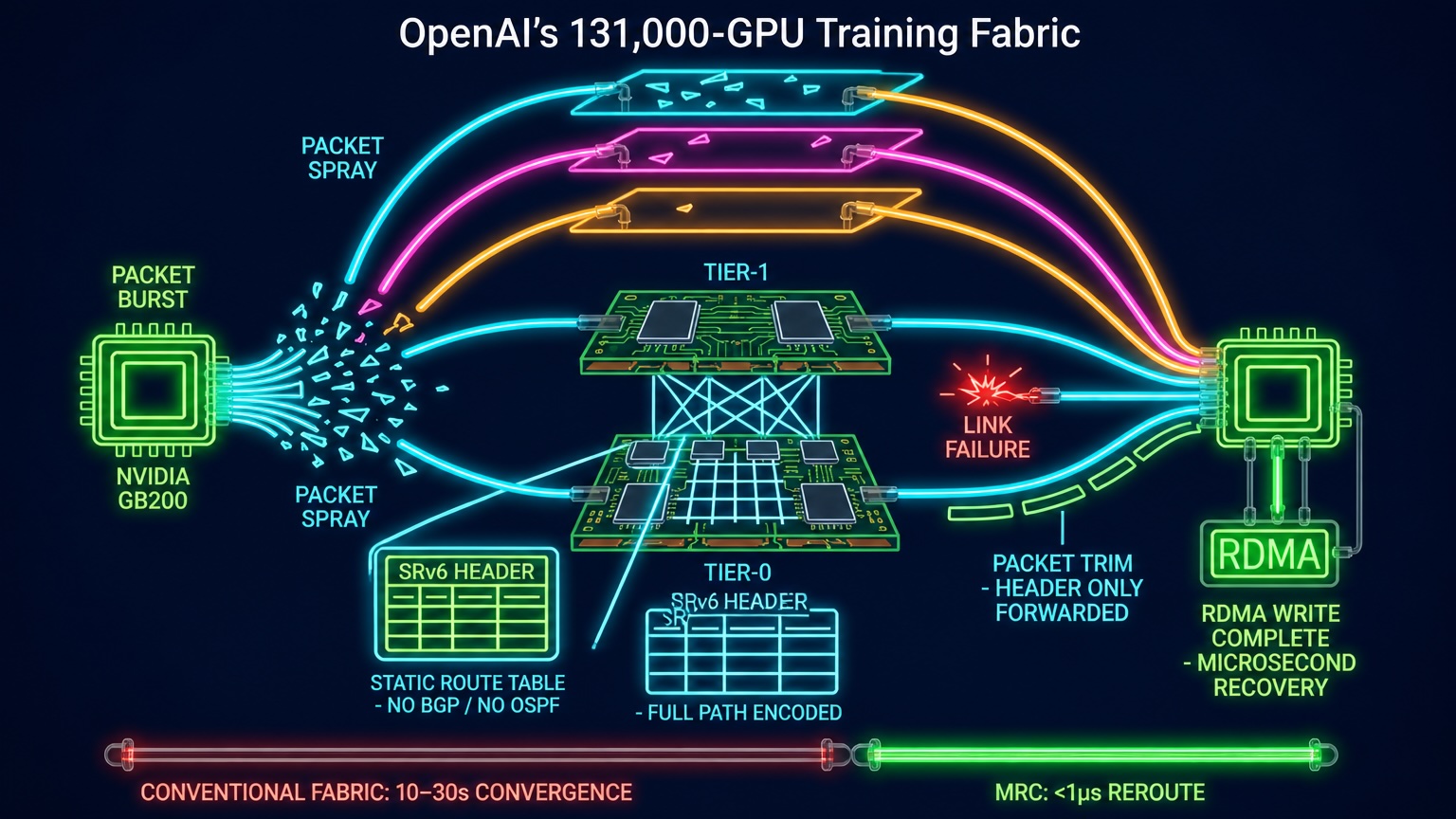
Nếu ai đó đưa cho bạn một danh sách thiết kế mạng cho một hệ thống kết nối 131.000 GPU với các yêu cầu: "Tắt mọi giao thức định tuyến", "Chấp nhận mất gói tin cố ý", và "Phun dữ liệu qua hàng trăm đường ngẫu nhiên", bạn có lẽ sẽ nghĩ rằng người viết đó chưa bao giờ vận hành một mạng thực tế nào.
Tuy nhiên, một liên minh gồm OpenAI, AMD, Broadcom, Intel, Microsoft và NVIDIA đã xây dựng chính xác một hệ thống như vậy — và âm thầm lật ngược ba thập kỷ đồng thuận về cách mạng trung tâm dữ liệu hiệu suất cao nên hoạt động.
Giao thức này được gọi là MRC (Multipath Reliable Connection), được phát hành vào ngày 5 tháng 5 năm 2026 thông qua Dự án Máy tính Mở (Open Compute Project). Bài báo cáo đi kèm đã tiết lộ cách MRC được triển khai trên các siêu máy tính NVIDIA GB200 khổng lồ của OpenAI, bao gồm cả site Stargate và siêu máy tính Fairwater của Microsoft. MRC chính là công nghệ nền tảng giúp huấn luyện các mô hình AI tiên tiến nhất hiện nay như ChatGPT và Codex.
Điều đáng chú ý nhất là MRC đã loại bỏ hoàn toàn lớp điều khiển Layer 3 khỏi mạng. Không OSPF, không BGP, không IS-IS. Các bộ chuyển mạch (switch) trong hệ thống duy trì trạng thái chuyển tiếp động bằng không. Đây là sự loại bỏ định tuyến động mạnh mẽ nhất từng được ghi nhận trong một hệ thống huấn luyện AI sản xuất.
Vấn đề: Một điểm nghẽn làm chậm 100.000 GPU
Quá trình huấn luyện tiền huấn (pretraining) đồng bộ diễn ra theo từng bước khóa. Mỗi bước huấn luyện liên quan đến hàng triệu lần chuyển dữ liệu giữa hàng nghìn GPU. Bước này không thể tiến triển cho đến khi chuyển dữ liệu chậm nhất hoàn thành.
Ở quy mô 100.000 GPU, thời gian của mỗi vòng trao đổi dữ liệu được quyết định bởi độ trễ đuôi (tail latency) — những trường hợp ngoại lệ chậm nhất — chứ không phải mức trung bình. Một liên kết bị tắc nghẽn, một va chạm luồng dữ liệu, hay một bộ đệm switch tràn có thể làm hàng nghìn GPU bị đình trệ trong vài mili-giây. Với chi phí vận hành khoảng 300.000 USD mỗi giờ cho một cụm 100.000 GPU, việc đình trệ 10 mili-giây lặp lại hàng nghìn lần là một khoản lãng phí khổng lồ.
MRC được thiết kế không chỉ để tăng băng thông mà còn cung cấp băng thông có thể dự đoán, ngay cả khi có sự cố, với một mặt phẳng điều khiển đủ đơn giản để một nhóm nhỏ có thể quản lý nhiều siêu máy tính cùng lúc.
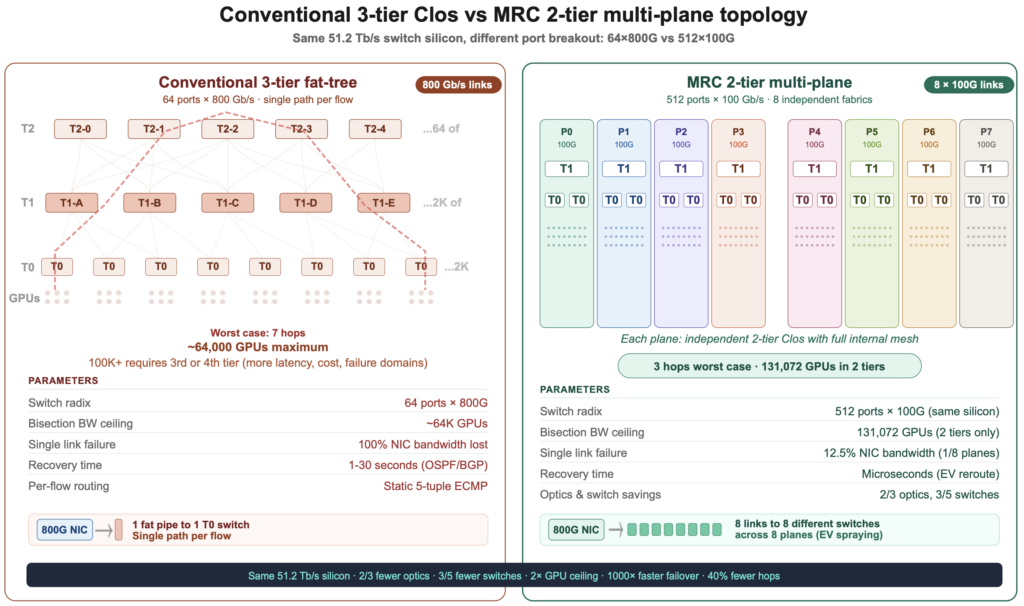 So sánh kiến trúc mạng 3 tầng truyền thống và 2 tầng của MRC
So sánh kiến trúc mạng 3 tầng truyền thống và 2 tầng của MRC
Kiến trúc: Chia nhỏ để làm chủ
Thay vì xử lý một card mạng 800 Gb/s như một đường ống lớn, MRC chia nó thành tám đường nối 100 Gb/s, mỗi đường kết nối đến một switch khác nhau. Điều này tạo ra tám mặt phẳng mạng song song, hoạt động độc lập.
Trong kiến trúc Clos fat-tree truyền thống với các cổng 800 Gb/s, bạn cần tới 4 tầng switch để hỗ trợ khoảng 64.000 GPU với băng thông song phương đầy đủ. Nhưng với MRC, cùng một con chip switch 51.2 Tb/s nhưng cấu hình ở tốc độ 100 Gb/s mỗi cổng sẽ cho ra 512 cổng. Điều này cho phép xây dựng một mạng hai tầng hỗ trợ tới 131.072 GPU với băng thông tối đa.
Điều này mang lại lợi ích to lớn về độ trễ (chỉ tối đa 3 nhảy so với 5-7 nhảy truyền thống), giảm số lượng switch và quang học cần thiết. Hơn nữa, nếu mất một đường nối 100 Gb/s trong mạng đa mặt phẳng của MRC, GPU chỉ mất 0,4% băng thông và vẫn có thể tiếp tục hoạt động bằng 7 đường còn lại mà không cần dừng việc huấn luyện.
Phun gói tin với Entropy Values
Các giao thức RDMA truyền thống thường ghim mỗi kết nối vào một đường mạng duy nhất. Điều này thất bại ở quy mô lớn do va chạm luồng (flow collisions). MRC loại bỏ hoàn toàn việc ghim luồng.
Thay vào đó, MRC gán cho mỗi Queue Pair (QP) một tập hợp 128 đến 256 giá trị entropy (EVs). Mỗi EV mã hóa một đường đi cụ thể qua một mặt phẳng mạng cụ thể. Người gửi sẽ xoay vòng qua tập hợp EV này gói tin này sang gói tin khác, "phun" các gói tin liên tiếp qua hàng trăm đường đi khác nhau trên tất cả tám mặt phẳng. Không có hai gói tin liên tiếp từ cùng một lần chuyển đi cùng một đường.
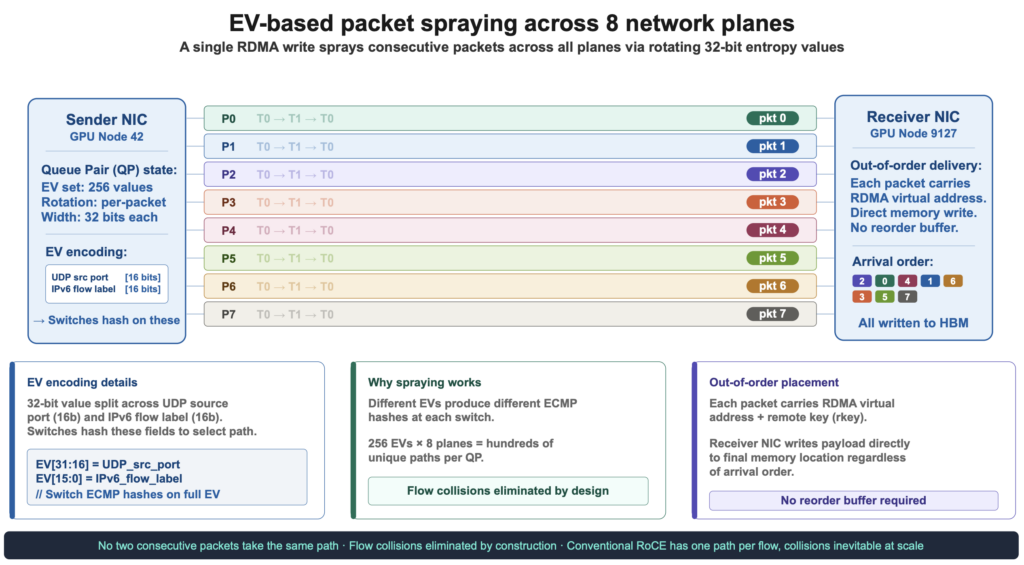 Cơ chế phun gói tin dựa trên giá trị entropy
Cơ chế phun gói tin dựa trên giá trị entropy
Mỗi EV mang theo một vài bit trạng thái sức khỏe. Khi người nhận phát hiện tắc nghẽn (thông qua đánh dấu ECN từ switch), nó sẽ phản hồi lại cho người gửi để tạm thời tránh EV đó. Nếu một gói tin bị mất, MRC giả định đường đó đã hỏng và ngừng sử dụng EV đó ngay lập tức.
Định tuyến nguồn tĩnh với SRv6
Đây là quyết định đi ngược lại intuition nhất. MRC tắt tất cả các giao thức định tuyến động (BGP, OSPF, IS-IS). Thay vào đó, MRC sử dụng IPv6 Segment Routing (SRv6) để mã hóa toàn bộ đường đi mà mỗi gói tin nên đi.
Người gửi nhúng chuỗi định danh switch trực tiếp vào địa chỉ đích của gói tin. Mỗi switch trên đường đi sẽ kiểm tra định danh của nó, xóa nó bằng cách dịch chuyển địa chỉ và chuyển tiếp đến bước tiếp theo. Không có tra cứu bảng định tuyến, không có hội tụ giao thức.
Bài báo giải thích logic này: "Chúng tôi đã đưa ra lập luận bất thường là tắt định tuyến động trong các switch vì chúng tôi không muốn hai cơ chế định tuyến thích ứng tương tác với nhau và định tuyến động không thêm vào bất cứ giá trị nào."
Việc loại bỏ định tuyến động mang lại ba lợi ích vận hành: chuyển tiếp xác định, loại bỏ các lỗi hội tụ và đơn giản hóa vận hành. Tuy nhiên, đánh đổi là tính toán đường đi được chuyển sang NIC. NIC MRC phải biết đủ về cấu trúc mạng để tạo các đường SRv6 hợp lệ.
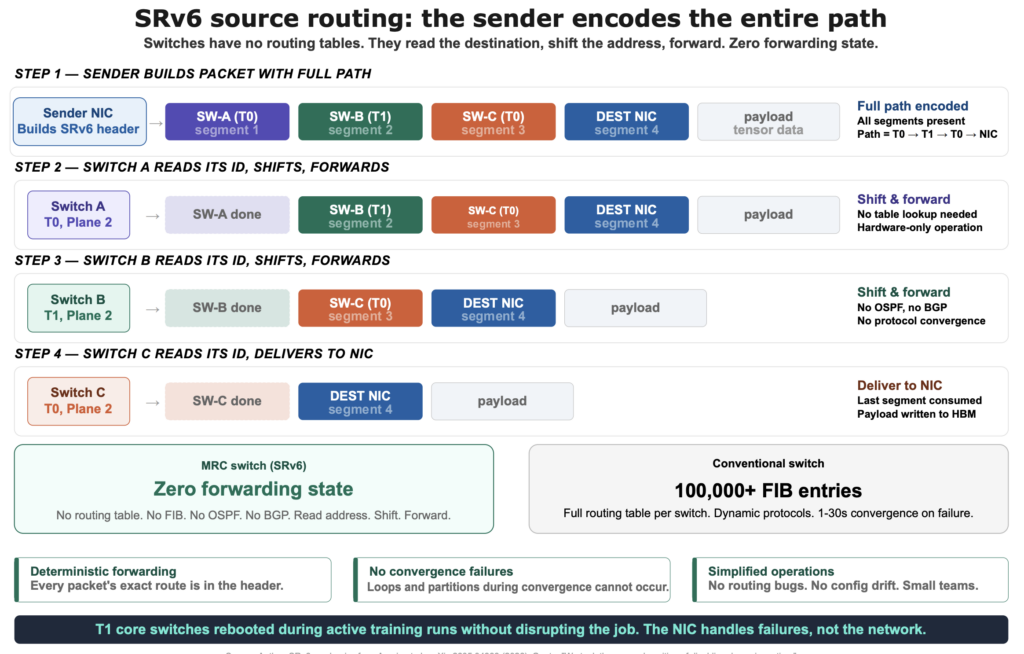 Cơ chế định tuyến nguồn tĩnh SRv6
Cơ chế định tuyến nguồn tĩnh SRv6
Chấp nhận mất gói: Tại sao MRC tắt PFC
Các mạng RDMA truyền thống dựa vào Priority Flow Control (PFC) để tạo ra mạng Ethernet không mất gói. MRC tắt rõ ràng PFC và chạy trên Ethernet nỗ lực tối đa (lossy).
Lý do là hiện tượng chặn đầu dòng (head-of-line blocking). Khi một khung PFC pause kích hoạt trên một cổng, nó có thể chặn lưu lượng destined cho các cổng khác chia sẻ cùng bộ đệm đầu vào. Trong một cụm huấn luyện lớn, việc này tạo ra các ngoại lệ độ trễ đuôi chính xác là những gì MRC muốn loại bỏ.
Giải pháp của MRC là sự kết hợp của ba cơ chế: truyền lại có chọn lọc (Selective Retransmission), cắt gói tin (Packet Trimming), và đặt bộ nhớ không theo thứ tự (Out-of-order memory placement). Điều này cho phép khôi phục nhanh hơn nhiều so với việc các khung PFC pause lan truyền.
ECN được tái định nghĩa: Cân bằng tải thay vì kiểm soát tắc nghẽn
Trong mạng thông thường, Explicit Congestion Notification (ECN) báo hiệu tắc nghẽn để người gửi giảm tốc độ truyền. MRC tái định nghĩa hoàn toàn ECN.
Trong kiến trúc đa mặt phẳng của MRC với băng thông song phương đầy đủ, tắc nghẽn tổng thể không nên tồn tại. Chỉ có sự mất cân bằng đường cục bộ. MRC sử dụng ECN làm tín hiệu tải trên mỗi đường. Người gửi không giảm tốc độ, mà chuyển hướng lưu lượng sang các đường ít tải hơn.
Kết luận
MRC đại diện cho sự thay đổi lớn hơn trong cách hạ tầng AI suy nghĩ về mạng. Thay vì xử lý mạng như một đường ống trong suốt, MRC coi mạng là một tài nguyên được quản lý với các tín hiệu sức khỏe có thể quan sát trên mỗi đường mà giao thức vận chuyển tận dụng chủ động.
Bằng cách làm cho NIC thông minh hơn và switch đơn giản hơn, MRC tạo ra một hệ thống linh hoạt hơn. Mặc dù các quyết định thiết kế này có vẻ "ngược đời", nhưng bằng chứng từ sản xuất của OpenAI và Microsoft cho thấy chúng hiệu quả ở quy mô chưa từng có. Đối với bất kỳ ai đang xây dựng cụm GPU quy mô lớn, MRC là một nghiên cứu điển hình quan trọng về việc phá vỡ các quy tắc cũ để đạt hiệu suất mới.
Bài viết liên quan

Công nghệ
Cisco sa thải 4.000 nhân sự dù doanh thu kỷ lục, chuyển hướng mạnh sang AI
14 tháng 5, 2026
Công nghệ
Fox Corp Đang Trong Tầm Ngắm Để Mua Đổi Roku: Một Bước Ngoặt Lớn Của Thị Trường Streaming
15 tháng 6, 2026

Phần cứng
Belkin ra mắt tay cầm sạc cho Switch 2: vừa cầm thoải mái vừa tăng thời lượng pin
04 tháng 6, 2026