
Nút thắt kín trong Học máy Lượng tử: Vấn đề đưa dữ liệu vào máy tính lượng tử
Học máy Lượng tử (QML) hứa hẹn khả năng xử lý trong không gian biểu diễn khổng lồ, nhưng trước khi tính toán, dữ liệu cổ điển phải được nhúng vào hệ thống lượng tử. Bài viết này khám phá một trong những nút thắt bị bỏ quên nhất trong QML: làm thế nào để đưa dữ liệu vào máy tính lượng tử một cách hiệu quả.

Học máy Lượng tử (QML) đang là một trong những lĩnh vực đầy hứa hẹn nhất của công nghệ hiện đại, mang đến tiềm năng tiếp cận các không gian biểu diễn dữ liệu theo cấp số nhân. Tuy nhiên, trước khi bất kỳ tính toán nào có thể diễn ra, dữ liệu cổ điển (classical data) mà chúng ta sử dụng hàng ngày phải được chuyển đổi và nhúng vào các trạng thái lượng tử (qubits). Quá trình này nghe có vẻ đơn giản, nhưng thực tế lại tạo ra một thách thức kỹ thuật to lớn, thường bị bỏ quên trong các thảo luận về QML.
Bài viết này sẽ đi sâu vào lý do tại sao việc đưa dữ liệu vào máy tính lượng tử lại trở thành một nút thắt nghẽn (bottleneck) ẩn, cũng như phân tích các phương pháp nhúng dữ liệu hiện tại và những đánh đổi cần phải lưu ý.
 Khái niệm về dữ liệu trong máy tính lượng tử
Khái niệm về dữ liệu trong máy tính lượng tử
Mạng nơ-ron cổ điển xử lý dữ liệu như thế nào?
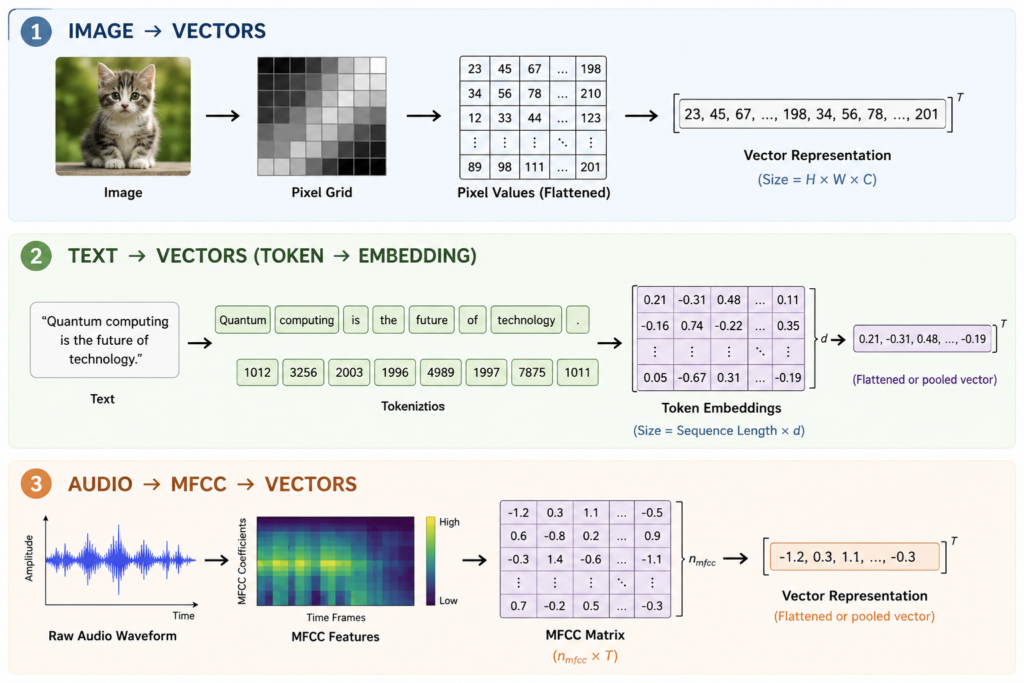
Trước khi đi sâu vào lượng tử, hãy nhìn lại cách các mạng nơ-ron (Neural Networks - NN) hoạt động. Sự thành công của Trí tuệ nhân tạo (AI) hiện đại phần lớn nhờ vào khả năng thu thập và xử lý khối lượng dữ liệu khổng lồ. Dù là hình ảnh, âm thanh hay văn bản, các mạng nơ-ron không "nhìn" dữ liệu theo cách con người làm.
Dưới lớp vỏ bọc, mọi thứ đều được chuyển đổi thành các vectơ số hoặc tensor. Ví dụ, một bức ảnh được biểu diễn bằng lưới các giá trị cường độ điểm ảnh, hoặc một câu văn trở thành các vectơ nhúng (token embeddings). Sự linh hoạt này cho phép các mô hình cổ điển xử lý nhiều loại dữ liệu khác nhau—từ dữ liệu chuỗi thời gian, không gian ảnh, đến dữ liệu nhiễu—một cách hiệu quả.
Máy tính lượng tử không thể đọc Bit
Máy tính lượng tử hoạt động dựa trên các nguyên lý hoàn toàn khác biệt. Thay vì xử lý các bit cổ điển (0 hoặc 1), chúng sử dụng các qubit, có thể tồn tại trong trạng thái chồng chập (superposition) của cả 0 và 1 đồng thời.
Một qubit ở trạng thái tổng quát thường được viết dưới dạng: |ψ⟩ = α |0⟩ + β |1⟩ trong đó α và β là các biên độ xác suất phức thỏa mãn điều kiện |α|² + |β|² = 1.
Vấn đề nằm ở chỗ: chúng ta sống trong một thế giới cổ điển nơi dữ liệu được lưu trữ dưới dạng bit. Một bộ xử lý lượng tử không thể trực tiếp đọc một bức ảnh hay một đoạn âm thanh như cách GPU xử lý cho mạng nơ-ron. Trước khi bất kỳ thuật toán lượng tử nào chạy, thông tin cổ điển này phải được mã hóa vào qubits—một nhiệm vụ phức tạp hơn nhiều so với suy nghĩ ban đầu.
Nhúng dữ liệu cổ điển vào trạng thái lượng tử
Quá trình chuyển đổi thông tin cổ điển sang trạng thái lượng tử được gọi là "nhúng dữ liệu lượng tử" (quantum data embedding) hoặc "chuẩn bị trạng thái lượng tử" (quantum state preparation). Các nhà nghiên cứu đã đề xuất nhiều phương pháp, nhưng hai kỹ thuật phổ biến nhất là mã hóa dựa trên góc (angle-based encoding) và mã hóa dựa trên biên độ (amplitude encoding).
Mã hóa dựa trên góc (Angle-based Encoding)
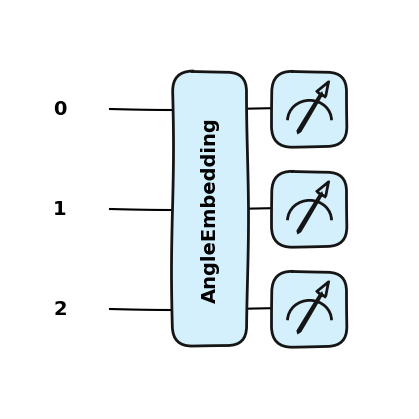
Đây là phương pháp đơn giản và phổ biến nhất. Trong kỹ thuật này, các đặc trưng cổ điển được mã hóa thành các góc xoay áp dụng lên qubits bằng các cổng lượng tử (quantum gates) như R-X, R-Y và R-Z.
Ví dụ, một vectơ đầu vào X = [x₁, x₂, x₃] có thể được nhúng bằng cách xoay các qubit tương ứng theo giá trị của từng đặc trưng.
 Mã hóa dựa trên góc xoay
Mã hóa dựa trên góc xoay
Mặc dù dễ triển khai, phương pháp này có nhược điểm lớn là khả năng mở rộng (scalability) kém. Về cơ bản, chúng ta cần số lượng qubits bằng với số lượng đặc trưng trong vectơ đầu vào. Điều này làm tốn kém tài nguyên lượng tử khi xử lý dữ liệu lớn.
Mã hóa dựa trên biên độ (Amplitude Encoding)
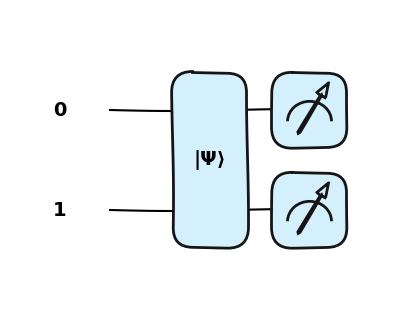
Mã hóa biên độ là một kỹ thuật khác, lưu trữ thông tin trực tiếp vào các biên độ của trạng thái lượng tử (các hệ số α và β). Ví dụ, vectơ X = [x₁, x₂, x₃, x₄] có thể được mã hóa chỉ với 2 qubits: ∣ψ(x)⟩= x₁∣00⟩ + x₂∣01⟩ + x₃∣10⟩ + x₄∣11⟩.
Đây là một ý tưởng cực kỳ hấp dẫn vì số lượng biên độ tăng theo cấp số nhân với số qubit. Chỉ với log₂(n) qubits, ta có thể biểu diễn n đặc trưng. Điều này làm cho mã hóa biên độ cực kỳ tiết kiệm không gian.
 Mã hóa dựa trên biên độ
Mã hóa dựa trên biên độ
Tuy nhiên, "của cho không bằng cách lấy". Mặc dù biểu diễn rất nhỏ gọn, quá trình chuẩn bị các trạng thái lượng tử này thường đòi hỏi số lượng thao tác tính toán khổng lồ, cũng theo cấp số nhân. Việc nạp dữ liệu vào trạng thái biên độ là một bài toán cực kỳ khó.
Nút thắt nghẽn trong việc nạp dữ liệu của Học máy Lượng tử
Các hệ thống Học máy hiện đại xử lý dữ liệu có kích thước và chiều cực lớn. Chúng ta đã thấy hai phương pháp nhúng cơ bản:
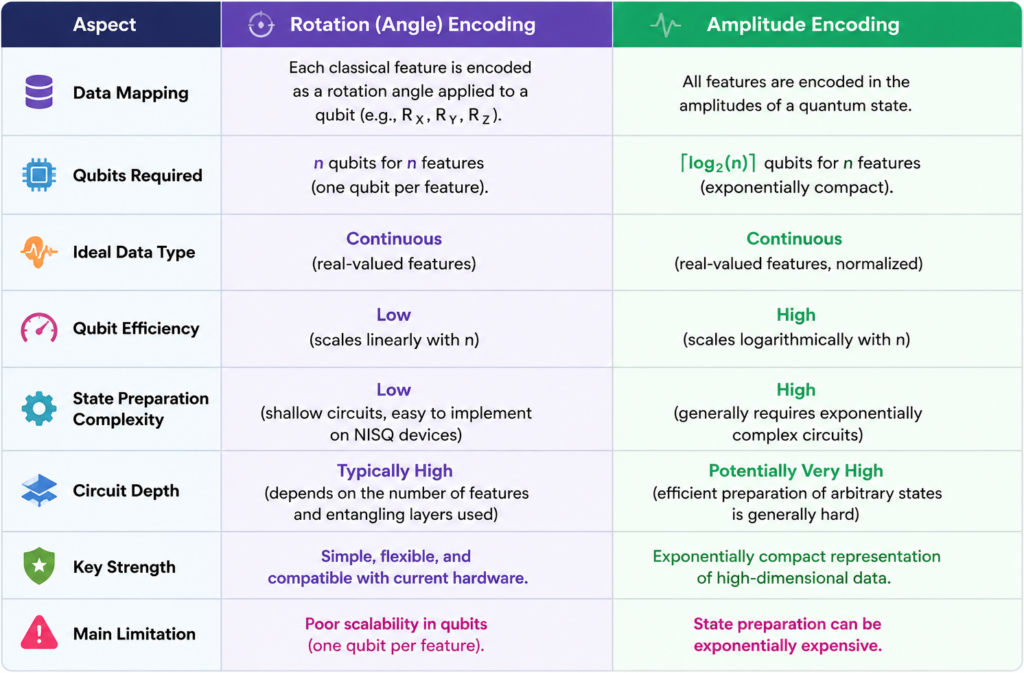
- Mã hóa góc: Dễ thực hiện nhưng tốn qubit (tài nguyên).
- Mã hóa biên độ: Tiết kiệm qubit nhưng tốn kém chi phí tính toán để chuẩn bị trạng thái.
Đây chính là nút thắt nghẽn thực tế lớn nhất trong QML hiện nay: Việc nạp thông tin cổ điển vào hệ thống lượng tử có thể tốn kém tính toán chính nó.
Trong nhiều trường hợp, chi phí chuẩn bị trạng thái có thể triệt tiêu hoặc làm mất đi các lợi thế lý thuyết mà thuật toán lượng tử mang lại. Đây là một sự tinh tế thường bị bỏ qua: một mô hình lượng tử có thể xử lý thông tin trong không gian Hilbert khổng lồ, nhưng nếu không thể đưa dữ liệu vào đó một cách hiệu quả thì toàn bộ quá trình sẽ trở nên vô nghĩa.
Hơn nữa, trong quá trình nhúng, các mối quan hệ cấu trúc trong dữ liệu gốc—như mối quan hệ không gian trong ảnh hoặc sự phụ thuộc thời gian trong chuỗi dữ liệu—cũng trở nên khó bảo toàn tự nhiên trong các biểu diễn lượng tử.
Kết luận
Học máy Lượng tử hứa hẹn mở ra cánh cửa đến các không gian biểu diễn khổng lồ, nhưng rào cản đầu tiên và khó khăn nhất lại nằm ở khâu chuẩn bị dữ liệu. Như đã phân tích, việc nhúng dữ liệu cổ điển vào trạng thái lượng tử không hề đơn giản và tạo ra một sự đánh đổi khó khăn giữa việc lưu trữ và việc nạp dữ liệu.
Các nhà nghiên cứu tại Google Quantum AI và nhiều tổ chức khác đang tích cực tìm kiếm các giải pháp mới như các kỹ thuật nhúng có khả năng học (learned quantum embeddings) hoặc tái nạp dữ liệu (data re-uploading) để vượt qua giới hạn này. Cho đến khi vấn đề này được giải quyết triệt để, tiềm năng thực sự của QML vẫn sẽ bị kìm hãm bởi chính "ngưỡng cửa" vào thế giới lượng tử này.
 Tóm tắt so sánh các phương pháp mã hóa
Tóm tắt so sánh các phương pháp mã hóa


