
Qdrant TurboQuant: Giải pháp nén vector mới có phải là "viên đạn bạc" cho tìm kiếm ngữ nghĩa?
Hầu hết các kỹ sư xem lượng tử hóa là sự đánh đổi giữa bộ nhớ và độ chính xác. TurboQuant đặt ra câu hỏi khó hơn: liệu có thể nén vector mà không làm phá vỡ cấu trúc hình học của chúng? Bài viết phân tích cơ chế xoay vector và hiệu suất thực tế của TurboQuant.

Hầu hết các kỹ sư nhìn nhận lượng tử hóa (quantization) dưới góc độ là sự đánh đổi giữa bộ nhớ và khả năng thu hồi (recall). Tiêu chuẩn thường dùng là Float32 với độ trung thực cao nhưng chi phí bộ nhớ lớn. Giải pháp cơ bản là lượng tử vô hướng (scalar quantization), giúp giảm mỗi giá trị xuống ít bit hơn (tỷ lệ nén khoảng 4×) với một chút giảm thiểu về độ chính xác. Mặc dù lượng tử nhị phân (binary quantization) mạnh mẽ hơn, thường đạt tỷ lệ nén 32×, nhưng kết quả truy xuất có thể trở nên không nhất quán do mất mát thông tin. Ngược lại, lượng tử tích (product quantization) có thể hiệu quả hơn, nhưng lại khó tinh chỉnh và vận hành trong môi trường sản xuất thực tế.
Vào đầu tháng 5 năm 2026, Qdrant đã phát hành TurboQuant, một phương pháp lượng tử hóa mới. Họ khẳng định rằng "TurboQuant có thể giảm việc sử dụng bộ nhớ mà không làm cho chất lượng truy xuất trở nên quá bất ổn". TurboQuant nghe có vẻ như tính năng mà các đội ngũ tìm kiếm vector mong muốn.
Tuy nhiên, câu hỏi đặt ra là liệu TurboQuant có thực sự hiệu quả khi kiểm tra trên các quy mô tập dữ liệu khác nhau hay không? Nó mang lại cải thiện thực sự so với các phương pháp lượng tử hóa phổ thông, hay lợi thế của nó phụ thuộc vào dữ liệu?
Bài viết này sẽ phân tích sâu về TurboQuant, so sánh với các phương pháp truyền thống và đánh giá xem liệu nó có nên là lựa chọn mặc định cho hệ thống tìm kiếm vector của bạn hay không.
1. Lượng tử hóa là gì?
Mỗi số float32 trong một vector chiếm 4 byte. Kết quả là một vector nhúng (embedding) 1536 chiều tốn 6 KB cho mỗi vector; với một triệu vector, cơ sở dữ liệu cần tới 6 GB chỉ cho mục lục.
Đây là lúc chúng ta cần Lượng tử hóa. Quá trình này thu nhỏ mỗi số trong vector thành một số byte nhỏ hơn. Phương pháp tiếp cận tiêu chuẩn là Lượng tử vô hướng (Scalar quantization). Nó bắt đầu bằng cách tìm giá trị nhỏ nhất và lớn nhất trên mỗi chiều. Sau đó, phạm vi đó được chia thành 255 khối (bin) bằng nhau. Mọi giá trị trong vector được làm tròn đến khối gần nhất và số khối đó được lưu dưới dạng một byte thay vì bốn byte.
 Quy trình lượng tử hóa cơ bản
Quy trình lượng tử hóa cơ bản
Vector nhúng Float32 gốc giờ đây trở thành vector uint8 với tỷ lệ nén 4 lần, nghĩa là kích thước lưu trữ nhỏ hơn 4 lần.
Sai số nhỏ ở hàng cuối cùng được gọi là sai số lượng tử (quantization error), và nó tích lũy trên 6 chiều của vector trong quá trình tính toán tích vô hướng. Điều này làm cho điểm số tương đồng bị sai lệch một chút.
Tuy nhiên, còn có các phương pháp nén mạnh mẽ hơn như 8x (4-bit), 16x (2-bit) hoặc 32x (1-bit). Nén càng nhiều, kích thước vector càng nhỏ, nhưng sai số so với gốc càng lớn.
2. Câu hỏi thực sự không phải là tỷ lệ nén
Câu hỏi thực sự là: Hình học vector còn lại sau khi nén là gì?
Các bộ lượng tử truyền thống, trong hầu hết các trường hợp, nén vector trực tiếp. Lượng tử vô hướng áp dụng cùng một lưới cố định cho mọi chiều, bất kể chiều đó chứa tín hiệu hữu ích hay nhiễu. Lượng tử nhị phân chỉ giữ lại bit dấu. Do đó, không phương pháp nào kiểm tra trước xem một số chiều có mang nhiều tín hiệu hơn các chiều khác hay không.
Qdrant 1.18 đã thay đổi mô hình này với sự tích hợp TurboQuant mới. Dựa trên thuật toán của Google Research trình bày tại ICLR 2026, TurboQuant xoay vector trước khi nén. Sự xoay ngẫu nhiên này phân tán phương sai đều hơn trên các chiều, giúp mỗi bit có thể lưu giữ nhiều thông tin hữu ích hơn.
TurboQuant không tốt hơn vì nó dùng ít bit hơn. Nó tốt hơn vì nó làm cho vector dễ nén hơn trước khi tiêu tốn các bit đó.
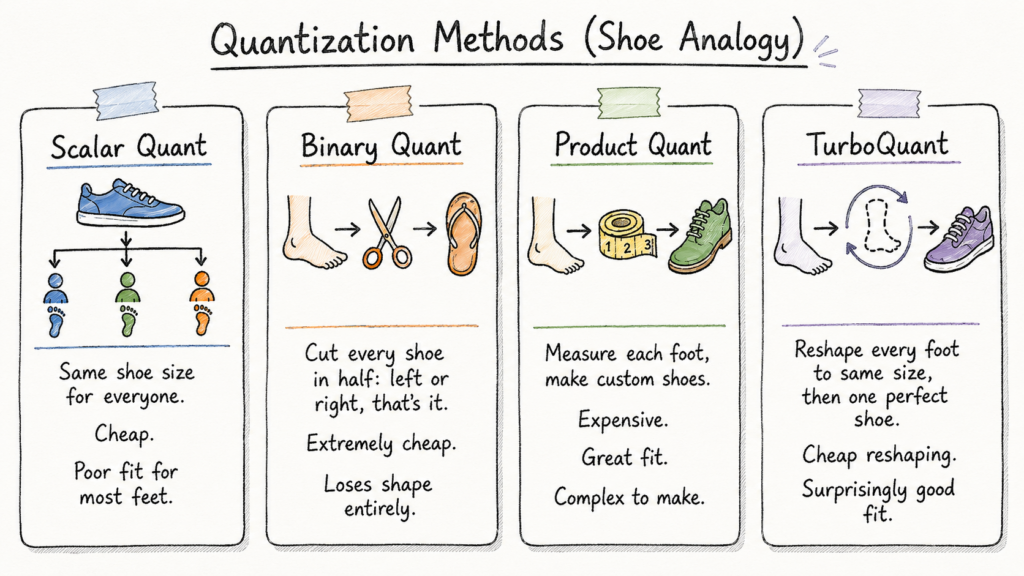 So sánh các phương pháp lượng tử hóa
So sánh các phương pháp lượng tử hóa
Sự khác biệt chính giữa TurboQuant và các phương pháp khác có thể hình dung như sau:
- Scalar Quant: Ép một lưới lên tất cả các chiều, giống như bắt mọi người đi cùng một cỡ giày.
- Binary Quant: Chuyển giá trị thành 0 hoặc 1, giống như cắt mỗi chiếc giày chỉ còn hai lựa chọn: trái hoặc phải. Nó rất rẻ nhưng vứt bỏ hầu hết thông tin hình dạng.
- Product Quant: Học sách mã cho mỗi không gian con, vừa vặn cho từng chân. Rất tốt nhưng cực kỳ tốn kém.
- TurboQuant: Làm cho tất cả các chiều trông giống nhau trước, sau đó dùng một sách mã được thiết kế tốt. Giống như thay đổi kích thước mọi chân để giống nhau rồi dùng một cỡ giày cho tất cả.
3. TurboQuant tóm tắt: Xoay trước, Nén sau
Mọi vector trong mô hình nhúng đều có cấu trúc. Một vector nhúng 1536 chiều có thể mang phần lớn tín hiệu hữu ích chỉ trong một tập hợp nhỏ các tọa độ. Các chiều còn lại thường đóng góp ít hơn nhiều, nhưng chúng vẫn xuất hiện trong mọi vector, thêm nhiễu và làm cho so sánh khoảng cách kém tin cậy hơn.
3.1 Quy trình TurboQuant
Ý tưởng rất đơn giản. Trước khi nén, hãy xoay vector thông qua một phép xoay trực giao ngẫu nhiên. Phép xoay đó không thay đổi khoảng cách — nó chỉ phân phối lại năng lượng sao cho mỗi chiều mang lại khoảng cùng một lượng thông tin. Sau đó, một sách mã được tính toán trước được áp dụng cho các vector đã xoay, và nó có thể xử lý tất cả các chiều tốt như nhau. Không cần tinh chỉnh theo từng chiều. Không cần huấn luyện trên dữ liệu của bạn.
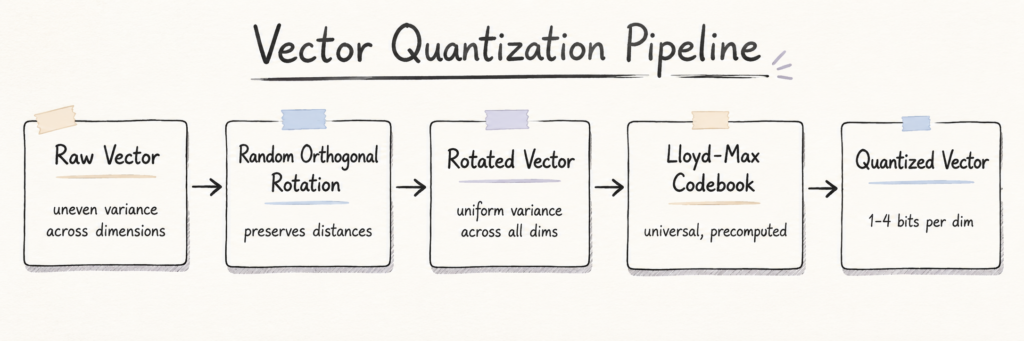 Quy trình TurboQuant
Quy trình TurboQuant
3.2 Tác động của việc xoay đối với tọa độ
Trước khi xoay, một vài chiều mang phần lớn năng lượng. Phần còn lại mang ít tín hiệu hơn và thường nhiều nhiễu hơn. Sau khi xoay, mỗi chiều mang năng lượng gần như bằng nhau và lượng thông tin tương đương.
Tuy nhiên, điều này có thực sự có nghĩa là sự biến đổi năng lượng bảo toàn thông tin quan trọng và duy trì khoảng cách tương đối so với vector gốc không?
Các thử nghiệm cho thấy sau khi áp dụng TurboQuant cho vector gốc A, khoảng cách giữa vector mới A và Vector B hầu như không thay đổi so với vector gốc A và Vector B. Điều này chứng minh rằng hình học quan trọng giữa các vector vẫn được bảo toàn và độ thu hồi được duy trì ở mức cao.
3.3 Qdrant áp dụng TurboQuant trong Cơ sở dữ liệu như thế nào?
Có 2 quá trình riêng biệt trên Qdrant:
Quá trình lập chỉ mục (Indexing process): Vector được xử lý như sau: vector gốc -> chuẩn hóa/chuẩn bị tùy theo metric -> đệm nếu cần -> xoay Hadamard -> hiệu chỉnh theo tọa độ tùy chọn -> gán tâm Lloyd-Max -> mã TurboQuant đã đóng gói.
Một yếu tố quan trọng mà Qdrant giới thiệu là Tái chuẩn hóa độ dài (Length Renormalization), hay còn gọi là hệ số tỷ lệ. Nó xảy ra sau khi lượng tử, khi Qdrant đo xem vector tái tạo bị ngắn đi bao nhiêu so với độ dài gốc, lưu tỷ lệ đó dưới dạng hệ số tỷ lệ cho mỗi vector, sau đó áp dụng nó trong quá trình chấm điểm tại thời điểm truy vấn.
Tại sao cần Tái chuẩn hóa độ dài? Có một quan sát sau khi lượng tử: Vector lượng tử chỉ đúng hướng nhưng lại quá ngắn. Khi tính toán tích vô hướng giữa một vector lượng tử và một truy vấn đã được mã hóa, bạn đang tính toán tích của một vector hơi quá ngắn, dẫn đến điểm số luôn thấp hơn. Qdrant gọi đây là "thiên lệch làm giảm độ thu hồi" (recall-degrading bias). Để khắc phục, chúng ta cần một hệ số để nhân lại nó trong giai đoạn chấm điểm.
Quá trình tại thời điểm truy vấn (Query Time Process): Truy vấn được xoay và chuyển đổi thành biểu diễn chấm điểm SIMD. Qdrant sử dụng chấm điểm bất đối xứng để so sánh truy vấn đã mã hóa đó trực tiếp với các mã TurboQuant đã đóng gói. Sau đó, hệ số tỷ lệ được lưu trữ sẽ được nhân với điểm số.
4. Nên thử phương pháp nào trước?
Qdrant cung cấp nhiều lựa chọn lượng tử, và TurboQuant cũng có các biến thể nén bit khác nhau như bits4, bits2, bits1.5 và bits1. Theo tài liệu của họ, độ sâu bit thấp hơn cung cấp khả năng nén cao hơn với chi phí là độ chính xác.
Lời khuyên chung là bắt đầu với TurboQuant 4-bit làm điểm cân bằng mặc định. Nếu bộ nhớ là ưu tiên tuyệt đối, hãy xem xét TurboQuant 1.5-bit kết hợp với chấm điểm lại (rescoring).
5. Bắt đầu: Thử nghiệm đầu tiên
Bạn chỉ cần thay đổi một cấu hình trong code Qdrant hiện tại để bật TurboQuant. Các bộ sưu tập hiện có của bạn vẫn không bị ảnh hưởng.
from qdrant_client import QdrantClient, models
client = QdrantClient("localhost", port=6333)
# Bộ sưu tập mới — thay đổi một cấu hình
client.create_collection(
collection_name="my_collection",
vectors_config=models.VectorParams(
size=1536,
distance=models.Distance.COSINE,
),
quantization_config=models.TurboQuantization(
turbo=models.TurboQuantQuantizationConfig(
bits=models.TurboQuantBitSize.BITS4,
always_ram=True,
)
),
)
# Bộ sưu tập hiện có — vá mà không cần tạo lại vector
client.update_collection(
collection_name="existing_collection",
quantization_config=models.TurboQuantization(
turbo=models.TurboQuantQuantizationConfig(
bits=models.TurboQuantBitSize.BITS4,
always_ram=True,
)
),
)
6. Benchmark: Lý thuyết có đúng không?
Để kiểm tra TurboQuant chống lại mọi bộ lượng tử khác của Qdrant trên các vector nhúng thực, tôi đã chạy nhiều bài kiểm tra ở các kích thước khác nhau (10K, 50K và 100K vector).
6.1 Tại sao dùng tập dữ liệu DBpedia?
Tôi chọn tập dữ liệu nhúng DBpedia vì nó có tỷ lệ phương sai tọa độ là 233.5x — tính dị hướng cao (highly anisotropic). Một vài chiều mang phần lớn tín hiệu; phần còn lại mang nhiễu. Đây chính là phân phối mà bước xoay của TurboQuant nên giúp ích nhiều nhất.
6.2 Độ thu hồi (Recall) theo quy mô
Có bốn điểm nổi bật:
- Độ thu hồi của TQ không đổi khi tập dữ liệu phát triển. Trong khi Lượng tử nhị phân giảm từ 0.916 xuống 0.78 khi kích thước tập dữ liệu tăng gấp đôi, các biến thể TurboQuant giữ vững tốt hơn nhiều.
- Hầu hết các biến thể TQ gần với Float32 và Scalar Quantization về độ thu hồi. Ngoại trừ TQ 1-bit và TQ 4-bit, kết quả TurboQuant vẫn có thể so sánh rộng rãi với đường cơ sở Float32.
- TQ 4-bit mang lại sự đánh đổi tốt nhất giữa độ chính xác và nén. Nó đạt độ thu hồi gần với Scalar Quantization trong khi sử dụng khoảng một nửa dung lượng lưu trữ: nén 8× so với 4× của Scalar.
- Rescoring (Chấm điểm lại) phục hồi nhiều khoảng trống độ thu hồi. TQ 1-bit cải thiện đáng kể với rescoring.
6.3 Độ trễ (Latency) theo quy mô
Câu chuyện về độ trễ rất rõ ràng: rescoring thêm một chút chi phí, nhưng không nhiều. Ở 100K vector, TQ 4-bit + rescore chạy trong 6.4 ms, nhanh hơn Float32 ở mức 7.6 ms và chỉ chậm hơn Scalar Quantization một chút ở mức 6.8 ms.
6.4 Dung lượng lưu trữ
TQ 1-bit có cùng dấu chân lưu trữ với Binary Quantization: cả hai đều dùng 18 MB, hoặc khoảng nén 32×. TQ 2-bit và TQ 4-bit dùng nhiều lưu trữ hơn để bảo toàn nhiều thông tin hơn. Ngay cả khi vậy, cả hai vẫn nhỏ hơn nhiều so với Scalar Quantization.
6.5 Thời gian xây dựng chỉ mục
TQ là cấu hình nhanh nhất ở mức 64s cho 50K vector, chủ yếu vì việc trích xuất bit dấu rất rẻ. Điều này cho thấy rằng việc xoay và hiệu chỉnh sách mã chỉ thêm một chi phí lập chỉ mục nhỏ.
7. Điều này có ý nghĩa gì trong thực tế
Nhìn chung, TurboQuant trông đầy hứa hẹn khi chúng ta ưu tiên sự cân bằng giữa nén và chất lượng truy xuất ổn định. Kết quả cho thấy không phải tất cả các định dạng nén đều hoạt động giống nhau khi tập dữ liệu phát triển.
- TQ 2-bit và TQ 4-bit giữ độ thu hồi tương đối ổn định khi kho dữ liệu phát triển. Điều này cho thấy bước xoay của TurboQuant giúp bảo toàn nhiều thông tin hữu ích hơn trong mỗi bit.
- TQ 4-bit mang lại sự cân bằng tốt nhất giữa độ thu hồi và nén. TQ 4-bit đạt độ thu hồi gần với Scalar Quantization nhưng với tỷ lệ nén gấp đôi. Điều này có nghĩa là TQ 4-bit có thể tiết kiệm khoảng một nửa chi phí bộ nhớ.
- TQ 1.5-bit với rescoring là lựa chọn mạnh nhất cho nén cực đoan. Nó cung cấp khoảng 24× nén trong khi giữ độ thu hồi gần với Float32 sau khi rescoring.
- TQ với rescoring là mô hình an toàn hơn khi bạn cần cân bằng độ trễ và độ chính xác.
8. Hạn chế của TurboQuant
TurboQuant cải thiện sự đánh đổi nén. Nhưng nó không loại bỏ hoàn toàn sự đánh đổi đó.
Nó cũng vẫn còn mới. Được ra mắt vào ngày 11 tháng 5 năm 2026, nên kinh nghiệm sản xuất thực tế vẫn còn hạn chế. Cách tiếp cận an toàn là đơn giản: benchmark nó trước, sau đó quyết định xem nó có nên trở thành mặc định của bạn hay không.
Một số hạn chế cần cân nhắc:
- Sự trưởng thành: Dữ liệu của bạn có thể hoạt động khác biệt. TurboQuant nên được coi là một lựa chọn mạnh mẽ, không phải là sự thay thế tự động.
- Tốc độ: TurboQuant có thể chậm hơn Binary Quantization ở cùng kích thước lưu trữ. Nếu bạn quan tâm đến tốc độ hơn là độ thu hồi, Binary Quantization vẫn là lựa chọn tốt hơn.
- Chi phí hiệu chỉnh: TurboQuant cần một bước hiệu chỉnh một lần cho mỗi phân đoạn. Nếu hệ thống của bạn tạo nhiều phân đoạn hoặc xây dựng lại chỉ mục thường xuyên, bước thêm này nên được xem xét.
- Loại khoảng cách: TurboQuant hoạt động tốt nhất với L2, tích vô hướng và độ tương đồng Cosine. Nó không bảo toàn khoảng cách L1 hoặc Manhattan theo cùng cách đó.
Bài học chính không phải là "luôn luôn sử dụng TurboQuant". Bài học chính là kiểm tra những gì quan trọng đối với dữ liệu của bạn. TurboQuant dịch chuyển sự đánh đổi theo hướng tốt hơn. Nhưng nó không làm cho nén trở nên miễn phí.
Kết luận
TurboQuant là một lựa chọn mới mạnh mẽ, đặc biệt hữu ích khi kết hợp với rescoring và cài đặt bit vừa phải. Nó đặc biệt hữu ích khi bạn muốn độ thu hồi tốt hơn từ một ngân sách bộ nhớ nhỏ. Tuy nhiên, nó không nên được sử dụng mù quáng. Hãy benchmark trên các vector nhúng của chính bạn trước và đo lường kỹ lưỡng trước khi chuyển sang sản xuất.
Bài viết liên quan

Phần mềm
OpenSSL Khắc Phục Lỗ Hổng Nghiêm Trọng Được Phát Hiện Bởi Trí Tuệ Nhân Tạo
09 tháng 6, 2026

Phần mềm
CVE Lite CLI: Công cụ giúp lập trình viên phát hiện và sửa lỗi phụ thuộc trong vài giây
05 tháng 6, 2026

Phần mềm
Microsoft vá gần 200 lỗ hổng bảo mật, bao gồm lỗi BitLocker và tấn công từ chối dịch vụ
09 tháng 6, 2026