
RAG đang "đốt tiền" như thế nào? Tôi đã xây dựng lớp kiểm soát chi phí để khắc phục
Hầu hết các hệ thống RAG được tối ưu hóa cho chất lượng câu trả lời chứ không phải chi phí, dẫn đến lãng phí ngân sách lớn. Bài viết này phân tích một lớp kiểm soát chi phí hoàn chỉnh, kết hợp bộ nhớ đệm ngữ nghĩa, định tuyến truy vấn và cầu dao, giúp giảm tới 85% chi phí LLM mà không làm giảm chất lượng.

RAG (Retrieval-Augmented Generation) đang "đốt tiền" như thế nào? Tôi đã xây dựng lớp kiểm soát chi phí để khắc phục
Hầu hết các hệ thống RAG hiện nay được tối ưu hóa cho chất lượng câu trả lời, nhưng lại bỏ qua chi phí – một điểm mù khiến ngân sách tăng vọt không kiểm soát. Trong bài viết này, tôi sẽ phân tích một lớp kiểm soát chi phí đã sẵn sàng đưa vào sản xuất, kết hợp bộ nhớ đệm ngữ nghĩa (semantic caching), định tuyến truy vấn (query routing), quản lý ngân sách token và cơ chế cầu dao (circuit breaker). Giải pháp này đã giúp giảm tới 85% chi phí LLM mà không làm giảm chất lượng trả lời.
Hệ thống hoạt động tốt – nhưng âm thầm làm rỗng ví
Tôi đã xây dựng một hệ thống RAG hoạt động hoàn hảo: chạy các truy vấn giống nhau qua cùng một pipeline và nhận về kết quả đầu ra y hệt mỗi lần. Trong quá trình test, mọi thứ đều ổn định, độ trễ thấp và câu trả lời chính xác.
Cho đến khi tôi xem lại nhật ký token.
Trong thiết lập của tôi, ngay cả những câu hỏi đơn giản như "RAG là gì?" hay "Định nghĩa tìm kiếm ngữ nghĩa." cũng đang được chuyển tới mô hình đắt đỏ nhất. Mỗi truy vấn lặp lại đều bị tính phí đầy đủ, mặc dù tôi đã trả lời chính xác câu hỏi đó mười phút trước. Mỗi yêu cầu đều lấy về mười đoạn văn (chunk), trong khi thực tế chỉ cần hai đoạn là đủ.
Hệ thống không bị hỏng. Nó chỉ bị "mù" về mặt tài chính. Và ở quy mô lớn, sự khác biệt đó không còn quan trọng nữa; tiền vẫn cứ tiêu đi.
Ba lý do khiến RAG lãng phí tiền theo thiết kế
RAG được thiết kế để giải quyết vấn đề chất lượng truy xuất, không phải vấn đề chi phí. Tuy nhiên, trong môi trường sản xuất, hai lớp này va chạm nhau và cái giá phải trả rất đắt.
Dưới đây là ba chế độ thất bại cụ thể:
- Vượt cấp cảnh báo ngữ cảnh (Context Window Over-Fetching): Hầu hết các triển khai mặc định lấy top-10 đoạn văn. Thực tế chỉ có 2-3 đoạn chứa câu trả lời, 7-8 đoạn còn lại chỉ là nhiễu. Bạn đang trả tiền cho những token thừa thãi này mỗi ngày.
- Không có lớp đệm (No Caching Layer): Hai người dùng hỏi cùng một câu hỏi cách nhau mười phút, hệ thống tạo ra cùng một embedding, lấy về cùng một đoạn văn và trả về cùng một câu trả lời. Bạn trả tiền LLM hai lần cho cùng một công việc.
- Không có định tuyến mô hình (No Model Routing): Một số pipeline mặc định sử dụng một mô hình duy nhất có hiệu suất cao cho mọi truy vấn, bất kể độ phức tạp. Một câu hỏi định nghĩa đơn giản không cần GPT-4.5 hay Claude Opus; nó cần một mô hình rẻ và nhanh.
 Thực tế về chi phí ở quy mô lớn
Thực tế về chi phí ở quy mô lớn
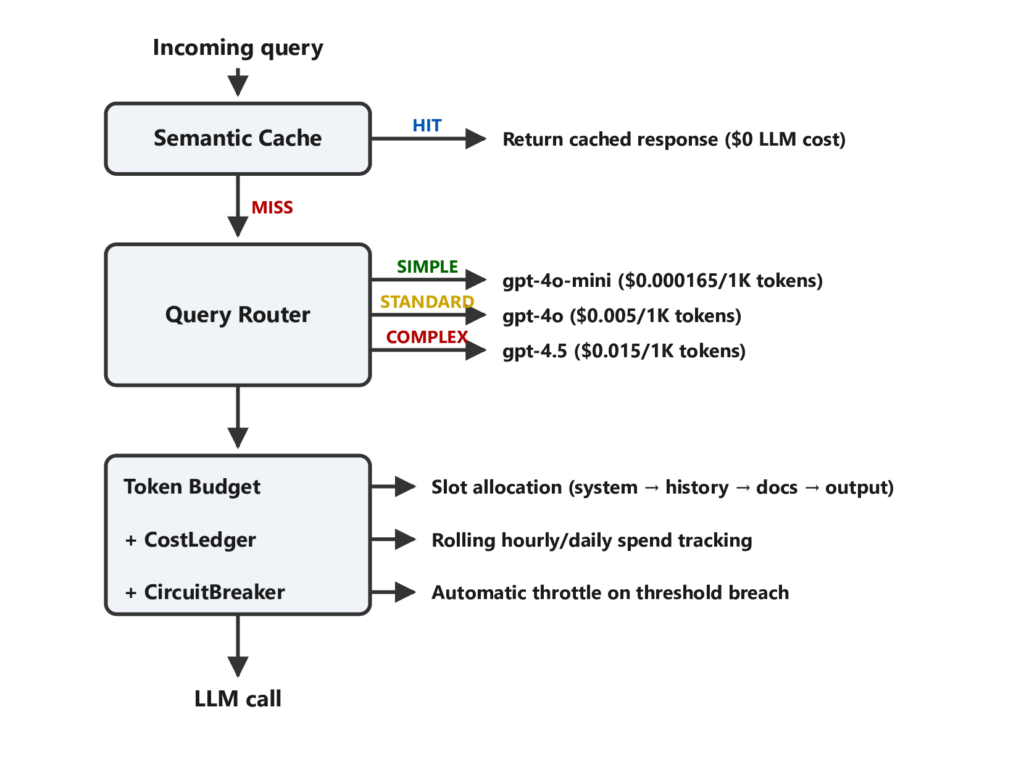
Kiến trúc: Bốn lớp, một hệ thống
Lớp kiểm soát chi phí bao gồm bốn thành phần, mỗi thành phần nhắm vào một chế độ thất bại khác nhau của hệ thống. Mỗi lớp có một nhiệm vụ duy nhất. Khi kết hợp lại, chúng khiến hệ thống nhận thức được chi phí tại mọi điểm ra quyết định.
 Sơ đồ kiến trúc lớp kiểm soát chi phí
Sơ đồ kiến trúc lớp kiểm soát chi phí
1. Bộ nhớ đệm ngữ nghĩa (Semantic Cache)
Đây là cách giảm chi phí đơn giản nhất trong toàn bộ hệ thống: Ngừng trả tiền cho LLM cho những câu hỏi bạn đã trả lời.
Mọi truy vấn đến đều được nhúng (embed) bằng vectorizer TF-IDF. Bộ nhớ đệm lưu giữ danh sách các cặp truy vấn-phản hồi trước đó, kèm theo nhúng của chúng. Khi một truy vấn mới đến:
- Nhúng truy vấn.
- Tính toán độ tương đồng cosine với tất cả các nhúng đã lưu trong bộ nhớ đệm.
- Nếu độ tương đồng tốt nhất ≥ ngưỡng (mặc định 0.75): trả về phản hồi đã lưu.
- Nếu lỡ (miss): gọi LLM, lưu kết quả.
Trong các bài kiểm tra thực tế, với bộ đệm đã được làm nóng (pre-seeded), tỷ lệ truy cập đạt tới 98.5%. Độ trễ khi trúng bộ đệm chỉ khoảng 4ms so với 700ms khi gọi LLM – cải thiện gấp 175 lần về tốc độ và gần như 100% về chi phí cho truy vấn đó.
2. Bộ định tuyến truy vấn (Query Router)
Không phải mọi truy vấn đều xứng đáng với cùng một mô hình. Bộ định tuyến sẽ phân loại mỗi truy vấn đến theo độ phức tạp và định tuyến nó đến tầng phù hợp một cách tự động.
Điểm số phức tạp là sự kết hợp có trọng số của ba tín hiệu độc lập:
- Điểm độ dài (20%): Số token được chuẩn hóa.
- Mật độ thực thể (30%): Tỷ lệ từ viết hoa, số và dấu câu kỹ thuật.
- Độ sâu suy luận (50%): Được tính toán từ các từ khóa liên quan đến suy luận như "so sánh", "phân tích", "tại sao", "ánh nạ" (trade-off).
Nếu truy vấn là dạng sự thật đơn giản (factoid) như "RAG là gì?", nó sẽ bị định tuyến nhanh chóng sang mô hình giá rẻ (như GPT-4o-mini). Trong bài kiểm tra, khoảng 81% các truy vấn đã được chuyển sang các mô hình chi phí thấp hơn mà không ảnh hưởng đến chất lượng.
3. Ngân sách Token (Token Budget)
Lớp này đảm bảo bạn không tiêu nhiều token hơn mức cần thiết cho một yêu cầu đơn lẻ. Nó hoạt động như một người quản lý tài chính vi mô cho mỗi lần gọi LLM, phân bổ ngân sách cho các phần như: system prompt, lịch sử chat, tài liệu truy xuất và kết quả đầu ra. Nếu tổng số token ước tính vượt quá ngân sách, nó sẽ ưu tiên cắt giảm tài liệu truy xuất trước khi cắt giảm phần đầu ra.
4. Cầu dao (Circuit Breaker)
Cầu dao cho RAG – dừng chi phí leo thang, phục hồi an toàn và giữ cho hệ thống LLM ổn định dưới áp lực.
 Cơ chế Circuit Breaker
Cơ chế Circuit Breaker
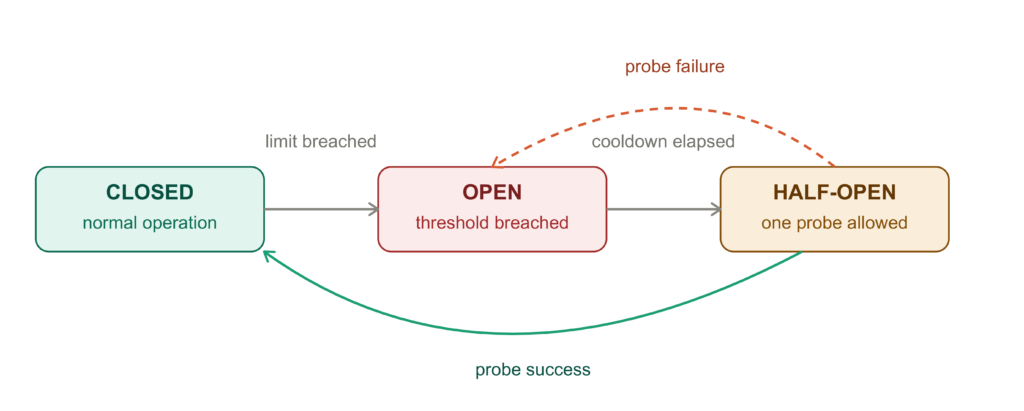
Cầu dao có ba trạng thái:
- CLOSED (Đóng): Hoạt động bình thường, mọi yêu cầu đi qua.
- OPEN (Mở): Ngưỡng bị vượt quá, các yêu cầu bị chặn hoặc hạ cấp.
- HALF_OPEN (Nửa mở): Thời gian làm nguội đã hết, một yêu cầu thăm dò được phép để kiểm tra khả năng phục hồi.
Nếu chi tiêu theo giờ hoặc theo ngày vượt quá giới hạn bạn đặt, cầu dao sẽ mở. Sau một khoảng thời gian cooldown, nó chuyển sang HALF_OPEN. Nếu yêu cầu thăm dò thành công, nó sẽ đóng lại.
Quan trọng: Bạn có thể cấu hình để khi cầu dao mở, hệ thống chuyển sang dùng mô hình rẻ hơn (downgrade) thay vì chặn hoàn toàn người dùng. Điều này giúp duy trì trải nghiệm dịch vụ ngay cả khi đang bảo vệ ngân sách.
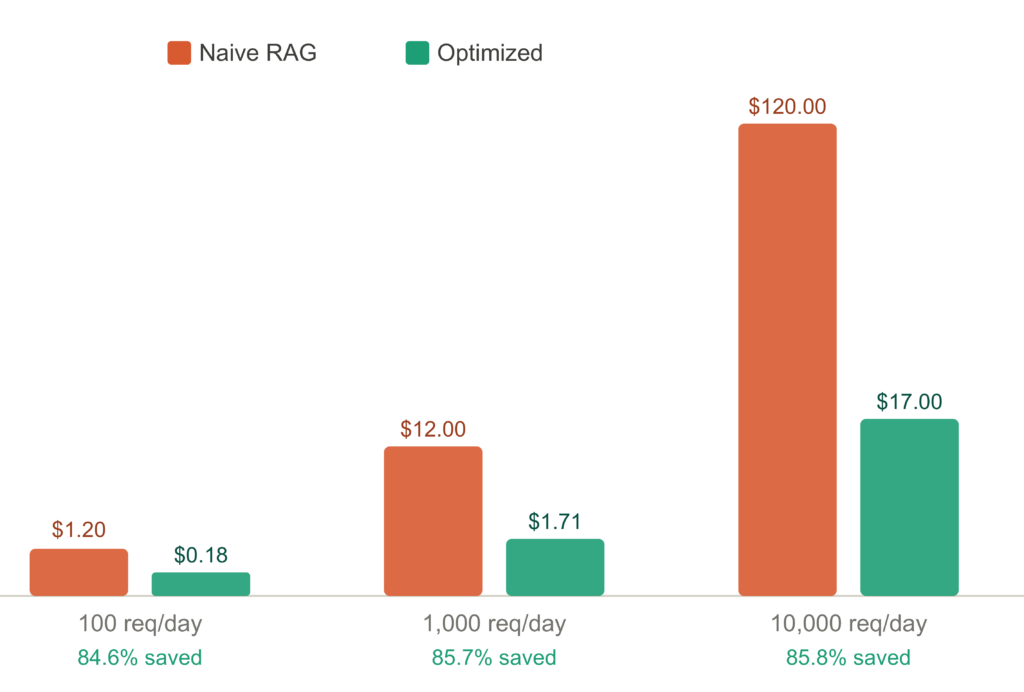
Kết quả thực tế: Tiết kiệm tới 85,8%
Tất cả các con số dưới đây đến từ các lần chạy hệ thống thực tế trên máy tính cá nhân.
Khi so sánh giữa hệ thống RAG "ngây thơ" (luôn dùng mô hình đắt nhất, không bộ đệm) và hệ thống đã tối ưu hóa ở quy mô 10.000 yêu cầu mỗi ngày:
- Chi phí RAG ngây thơ: $120/ngày.
- Chi phí đã tối ưu hóa: $17/ngày.
- Tiết kiệm: 85,8%.
Tính theo tháng, con số này tương đương việc tiết kiệm được khoảng $3.090 mỗi tháng. Phần trăm tiết kiệm ổn định ở mức ~85,8% khi trên 1.000 yêu cầu/ngày.
Những quyết định thiết kế trung thực
Giải pháp này sử dụng Python thuần túy để nhúng TF-IDF – không cần PyTorch hay sentence-transformers. TF-IDF so khớp các token chung thay vì ý nghĩa ngữ nghĩa sâu sắc. Nếu người dùng của bạn có xu hướng diễn đạt lại câu hỏi thay vì lặp lại nguyên văn, tỷ lệ trúng bộ đệm sẽ thấp hơn.
Ngoài ra, các ngưỡng định tuyến (simple_threshold=0.25, complex_threshold=0.65) được hiệu chỉnh trên tập dữ liệu truy vấn lĩnh vực RAG. Các lĩnh vực khác như pháp lý, y tế hoặc hỗ trợ khách hàng sẽ yêu cầu các giá trị ngưỡng khác nhau.
Kết luận
RAG giúp bạn có được câu trả lời đúng. Lớp kiểm soát chi phí này giúp bạn nhận được hóa đơn đúng.
RAG thất bại về chất lượng, và đã có nhiều công trình giải quyết vấn đề đó. Nhưng RAG cũng thất bại về chi phí, và sự thất bại này thường diễn ra thầm lặng – không có lỗi, không có cảnh báo, chỉ có hóa đơn tăng vọt.
Bằng cách chèn bốn lớp phòng thủ (bộ nhớ đệm ngữ nghĩa, bộ định tuyến, ngân sách token và cầu dao) vào giữa pipeline truy xuất và gọi LLM, bạn có thể đạt được sự tiết kiệm đáng kể mà không làm giảm chất lượng phản hồi. Điều tuyệt vời nhất? Hệ thống chạy hoàn toàn bằng Python thuần túy, không có khung công cụ nặng nề hay các phụ thuộc bên ngoài lớn.
Để tham khảo mã nguồn đầy đủ, bạn có thể tìm thấy trong kho GitHub được chia sẻ bởi tác giả (liên kết trong bài viết gốc).


