
Tại sao không nên để LLM quyết định sự thay đổi thời tiết
Hầu hết các ứng dụng thời tiết đều gặp khó khăn trong việc xác định khi nào sự thay đổi dự báo thực sự quan trọng. Việc giao phó việc này cho LLM thường thay thế các quy tắc vật lý xác định bằng sự phán đoán ngẫu nhiên, gây ra rủi ro trong các lĩnh vực nhạy cảm. Bài viết đề xuất kiến trúc Skygent, tách biệt logic quyết định (code) và phần giải thích (LLM) để đảm bảo tính chính xác và hiệu quả.
Hầu hết các ứng dụng thời tiết hiện nay đều gặp một vấn đề看似 đơn giản nhưng thực tế phức tạp: chúng hiển thị dự báo, nhưng không cho bạn biết khi nào dự báo đó thực sự thay đổi.
Điều này nghe có vẻ tầm thường, nhưng không phải vậy. Các hệ thống dự báo thời tiết số hiện đại (NWP) như ECMWF IFS tạo ra các dự báo cực kỳ chính xác ở độ phân giải khoảng 9 km, cập nhật vài giờ một lần. Dữ liệu đã rất tốt rồi.
Vấn đề không nằm ở dự báo, mà nằm ở sự chú ý: biết khi nào một thay đổi trong dữ liệu đó thực sự có ý nghĩa.
Tôi không học được điều này từ kỹ thuật phần mềm, mà từ những năm tháng nghiên cứu lý thuyết hỗn loạn (chaos theory) tại Instituto Balseiro. Khi làm việc với các hệ thống động, tôi đã gặp một ý tưởng hơi gây bất an: Một hệ thống có thể hoàn toàn xác định (deterministic) nhưng vẫn thực tế là không thể dự đoán.
Ý tưởng đó luôn đi theo tôi. Và nhiều năm sau, khi bắt đầu xây dựng các hệ thống AI, tôi nhận ra rằng nhiều hệ thống đang bỏ qua nó.
Vấn đề của sự thay đổi dựa trên "cảm giác"
Khi tôi thấy cách các nhà phát triển xây dựng các agent thời tiết, tôi nhận thấy một mô hình chung:
- Lấy dữ liệu dự báo.
- Cho vào LLM.
- Hỏi: "Thời tiết có thay đổi đáng kể không?"
Thoạt nhìn, điều này có vẻ hợp lý. Nhưng dưới góc độ vật lý, nó có vấn đề — ít nhất là với các vấn đề mà ranh giới quyết định đã được định nghĩa rõ ràng — bởi vì nó thay thế một ngưỡng xác định rõ ràng bằng một cách giải thích xác suất.
Trong một hệ thống hỗn loạn, tính "quan trọng" không phải là một phán đoán ngôn ngữ — nó là một ngưỡng được định nghĩa trên các biến như nhiệt độ, lượng mưa hoặc tốc độ gió. Nó phụ thuộc vào độ lớn, bối cảnh và khung thời gian.
LLM là một quá trình ngẫu nhiên (stochastic). Nó rất giỏi tạo ra ngôn ngữ, nhưng không được thiết kế để áp đặt các ranh giới xác định cho các hệ thống vật lý.
Khi bạn hỏi LLM xem dự báo có "thay đổi đáng kể" hay không, bạn đang yêu cầu một mô hình xác suất xấp xỉ một quy tắc xác định mà bạn có thể đã định nghĩa rõ ràng. Điều đó tạo ra sự biến đổi chính xác ở nơi bạn cần sự nhất quán.
Các chế độ thất bại rất tinh vi:
- Xu hướng được suy ra từ cách diễn đạt thay vì dữ liệu.
- Các quyết định không nhất quán trên các đầu vào tương tự.
- Các đầu ra không thể kiểm thử hoặc tái tạo.
Trong nhiều ứng dụng, điều đó có thể chấp nhận được. Nhưng trong nông nghiệp, năng lượng và hậu cần — nơi sự giảm 3°C là một chuyển pha cho cây trồng, một sự tăng phi tuyến nhu cầu năng lượng, hoặc một gián đoạn vận hành — thì không. Những quyết định này cần phải ổn định và có thể giải thích được.
Điều đó dẫn tôi đến một quy tắc đơn giản:
Nếu bạn có thể viết một câu lệnh assert cho nó, có lẽ bạn không nên sử dụng prompt.
Con đường dẫn đến vấn đề này
Sự nghiệp của tôi trông giống như một quỹ đạo trong không gian pha hơn là một đường thẳng. Một bằng tiến sĩ Marie Curie về động lực khí hậu, năm năm điều phối R&D tại viện khí tượng quốc gia Uruguay — phòng chống cháy rừng, dự báo mùa, thích ứng khí hậu — sau đó chuyển sang ML sản xuất tại Microsoft và Mercado Libre.
Quỹ đạo đó đã cho tôi một điều cụ thể: Tôi đã hiểu vật lý của dữ liệu, các chân trời kỹ năng của mô hình, và "thay đổi đáng kể" thực sự có ý nghĩa gì trong một hệ thống vật lý. Không phải là một sự trừu tượng phần mềm — mà là một delta có thể đo lường trên một biến với các giới hạn độ không chắc chắn đã biết.
Khi bắt đầu xây dựng các hệ thống AI, bản năng là ngay lập tức: đây là một vấn đề ngưỡng. Các ngưỡng thuộc về code, không phải về prompt.
Skygent là một biểu hiện của quan điểm đó — một agent được thiết kế không phải để hiển thị dự báo, mà để phát hiện các thay đổi có ý nghĩa trong đó.
Hệ thống chạy liên tục trên dữ liệu dự báo thực tế cho các sự kiện do người dùng định nghĩa, đánh giá các thay đổi mỗi vài giờ và chỉ kích hoạt cảnh báo khi các điều kiện định trước được đáp ứng. Trong thực tế, hầu hết các chu kỳ đánh giá không dẫn đến cảnh báo nào — chỉ có một phần nhỏ các thay đổi vượt qua ngưỡng ý nghĩa. Đó là điểm mấu chốt: tín hiệu, không phải nhiễu.
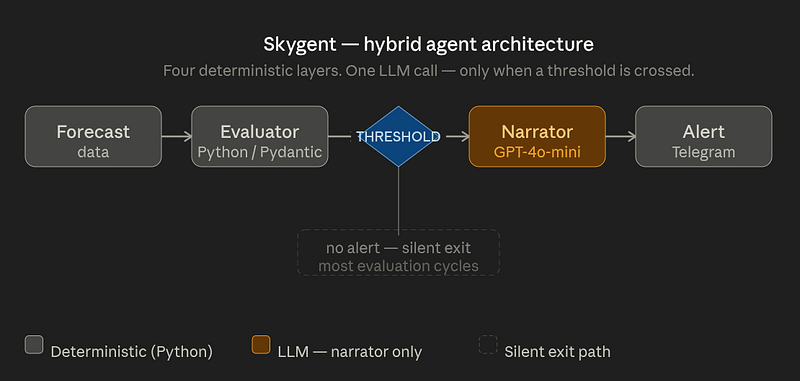
Kiến trúc hệ thống
Skygent tuân theo sự tách biệt rõ ràng qua năm lớp:
 Kiến trúc hệ thống Skygent
Kiến trúc hệ thống Skygent
Chỉ có một lớp gọi LLM.
Người gác cổng xác định (Deterministic Gatekeeper)
Tại lõi là một bộ đánh giá Python. Nó không "giải thích" — nó tính toán. Nó:
- So sánh các ảnh chụp nhanh dự báo được xác thực bởi Pydantic liên tiếp.
- Đánh giá các delta so với các ngưỡng có thể cấu hình.
- Kết hợp bối cảnh: loại sự kiện, độ nhạy của biến.
- Tính đến chân trời dự báo bằng cách sử dụng các giới hạn kỹ năng NWP đã thiết lập — một thay đổi trong dự báo 24 giờ không mang lại độ tin cậy giống như thay đổi trong dự báo 10 ngày.
Đây là nơi đưa ra quyết định. Mọi cảnh báo đều có một đường dẫn có thể truy xuất: biến nào thay đổi, bao nhiêu, ngưỡng nào bị vượt qua. Trong môi trường doanh nghiệp hoặc chính phủ, việc có thể giải thích tại sao một cảnh báo kích hoạt — mà không cần nói "mô hình cảm thấy như vậy" — là không thể thiếu.
Bộ kích hoạt (The Trigger)
Một cảnh báo chỉ kích hoạt nếu ngưỡng bị vượt qua. Nếu delta không vượt qua biên, không có gì xảy ra. Đây là một điều kiện nhị phân, có thể kiểm thử — không phải một cuộc gọi phán xét.
Người kể chuyện (The Narrator)
Chỉ sau khi quyết định được đưa ra, LLM mới mới vào quy trình. Vai trò của nó bị giới hạn nghiêm ngặt: lấy dữ liệu JSON có cấu trúc, dịch nó sang ngôn ngữ tự nhiên.
Ví dụ payload JSON được gửi đến GPT-4o-mini:
{
"event_name": "Đám cưới của Ana",
"variable": "precipitation_probability_max",
"from_value": 10.0,
"to_value": 50.0,
"delta": 40.0,
"horizon_days": 5.2,
"confidence": "medium"
}
Đầu ra:
"Xác suất mưa tăng từ 10% lên 50% cho khung thời gian sự kiện của bạn. Độ tin cậy ở mức trung bình do chân trời dự báo 5 ngày."
LLM không quyết định bất cứ điều gì. Nó chỉ giải thích.
Tại sao kiến trúc này có thể kiểm thử
Hầu như không thể đạt được độ phủ kiểm thử 100% trên một agent LLM thuần túy — bạn không thể viết các câu lệnh assert xác định trên các đầu ra xác suất.
Cách tiếp cận lai thay đổi điều này. Logic quyết định là Python thuần túy với các đầu vào được xác thực bởi Pydantic: 204 bài kiểm thử đơn vị, không có phụ thuộc LLM nào trong bộ kiểm thử. LLM chỉ xử lý giọng điệu kể chuyện — thứ thực sự hưởng lợi từ việc tạo ngôn ngữ tự nhiên.
Đây không chỉ là sự tiện lợi khi kiểm thử. Điều này có nghĩa là mọi quyết định hệ thống đưa ra đều có thể giải thích, tái tạo và xác minh độc lập với LLM.
Kích hoạt LLM theo sự kiện
Một agent ngây thơ gọi LLM trên mỗi chu kỳ thăm dò. Agent này thì không.
Skygent đánh giá mỗi 6 giờ. Nó chỉ gọi mô hình khi ngưỡng bị vượt qua — khoảng một hoặc hai lần mỗi tuần cho mỗi sự kiện được giám sát, so với ~28 cuộc gọi cho một agent thăm dò ngây thơ.
Với giá gpt-4o-mini (~$0.0001 cho mỗi câu chuyện), chi phí không đáng kể. Quan trọng hơn, chi phí tỷ lệ thuận với thông tin thực tế: bạn chỉ trả tiền cho cuộc gọi LLM khi có điều gì đó đáng để giao tiếp xảy ra.
Một ví dụ cụ thể
Ảnh chụp nhanh trước đó: Xác suất mưa 10%, Nhiệt độ tối đa 22°C, Gió 15 km/h Ảnh chụp nhanh hiện tại: Xác suất mưa 50%, Nhiệt độ tối đa 21.4°C, Gió 18 km/h Ngưỡng: Cảnh báo nếu xác suất mưa Δ > 20pp Tần suất đánh giá: Mỗi 6 giờ Kết quả: Cảnh báo kích hoạt → GPT-4o-mini tạo câu chuyện → Giao qua Telegram
 Ví dụ cảnh báo của Skygent
Ví dụ cảnh báo của Skygent
Khi mô hình này bị phá vỡ
Cách tiếp cận này không áp dụng ở khắp mọi nơi. Nó bị phá vỡ khi:
- Đầu vào không có cấu trúc hoặc mơ hồ.
- Ranh giới quyết định không thể được mã hóa thành các ngưỡng.
- Lý luận là mở rộng.
Trong những trường hợp đó, các kiến trúc ưu tiên LLM — như ReAct, Plan-and-Execute — sẽ hợp lý hơn.
Một lưu ý trung thực: các ngưỡng trong Skygent là mặc định có thể cấu hình — các điểm khởi đầu hợp lý được thông báo bởi thực tế khí tượng học, nhưng không được hiệu chuẩn dựa trên các lỗi dự báo lịch sử cho các trường hợp sử dụng cụ thể. Hiệu chỉnh dựa trên kết quả thực tế là bước tiếp theo tự nhiên cho bất kỳ triển khai dọc nào. Mô hình là âm thanh; các tham số chỉ là điểm khởi đầu.
Kết luận
Quyết định quan trọng nhất tôi đưa ra khi xây dựng hệ thống này không phải là chọn một mô hình hay một khung công cụ.
Đó là quyết định nơi không sử dụng LLM.
Hiện nay có xu hướng giao ngày càng nhiều việc cho các mô hình ngôn ngữ — để chúng tự tìm ra. Nhưng một số vấn đề đã có cấu trúc. Một số quyết định đã có ranh giới.
Khi chúng có, việc xấp xỉ chúng bằng ngôn ngữ là một bước đi sai lầm. Mã hóa chúng một cách rõ ràng thì tốt hơn.
Trong thực tế, điều này thường đi xuống một sự phân biệt đơn giản: sử dụng LLM để giải thích các quyết định, không phải để thay thế các quyết định đã được định nghĩa rõ ràng.
Toàn bộ triển khai — bộ đánh giá ý nghĩa, quy trình LangGraph, bot Telegram — có sẵn tại: github.com/ferariz/skygent
Bài viết liên quan
Phần mềm
Theo dõi hạn mức Claude Code ngay trên thanh menu macOS với claude-quota
10 tháng 6, 2026

Phần mềm
Triển khai mảng động trong C: Không cần Struct, không lưu trữ dung lượng
13 tháng 6, 2026

Phần mềm
MySQL 9.7: Bản LTS lớn đầu tiên kể từ 8.4 mang tính năng Enterprise xuống phiên bản Community
10 tháng 5, 2026