
Tôi đã xây dựng một Backend C++ để GPU ngừng "ăn gió": Tối ưu hóa hiệu suất LLM
Bài viết này cung cấp hướng dẫn chi tiết cách tối ưu hóa suy luận của các Mô hình Ngôn ngữ Lớn (LLM) thông qua việc loại bỏ chi phí đệm (padding) thừa thãi bằng cách sử dụng kỹ thuật đóng gói chuỗi dữ liệu tối ưu hóa cho phần cứng.
Tôi đã xây dựng một Backend C++ để GPU ngừng "ăn gió": Tối ưu hóa hiệu suất LLM
Đây là một hành trình vừa hài hước vừa thực tế về WarpGroup-Backend — bao gồm việc đóng gói thùng nhận biết VRAM, truyền bộ nhớ ghim (pinned-memory), và cách khiến LLM của bạn nhanh hơn gấp 5,89 lần bằng cách "thô lỗ" một chút với PyTorch.
Kho lưu trữ: github.com/AnubhabBanerjee/WarpGroup-backend
Tóm tắt nhanh: Việc chạy lô (batching) tiêu chuẩn cho LLM thường đệm các chuỗi ngắn bằng số 0 để chúng khớp với chuỗi dài nhất. GPU của bạn sẽ tận tụy thực hiện hàng tỷ phép nhân trên những con số 0 này — điều tương đương với việc trả tiền cho một đầu bếp để nấu một cái đĩa trống rỗng. WarpGroup-Backend thay thế điều này bằng một động cơ C++ nhỏ gọn nhồi các chuỗi dài độ thay đổi vào với nhau như một nhà vô địch chơi Tetris đầy lo âu. Kết quả: Tăng 2,08× tốc độ xử lý trên H100, 5,89× trên GTX 1080, và không còn lỗi Out of Memory (OOM).
1. Sự thật thú vị: Hầu hết "công việc" của GPU là giả
Nếu bạn từng chạy lô các văn bản có độ dài thay đổi qua một mô hình transformer, đây là những gì thực sự xảy ra (được kể lại một chút kịch tính):
Bạn: "GPU ơi, hãy tóm tắt giúp tôi 8 tài liệu này nhé." PyTorch: "Chắc chắn rồi. Để tôi làm cho tất cả chúng có cùng hình dạng trước đã." Bạn: "Đợi đã, độ dài của chúng là 80, 90, 110, 130, 95, 1850, 2000 và 60 token. Đừng—" PyTorch: "Đã đệm tất cả lên 2000. Chúc vui vẻ." 🫡 GPU: (vui vẻ đốt cháy khoảng một nửa sức mạnh tính toán và băng thông bộ nhớ trên các số 0) Hóa đơn AWS của bạn: bắt đầu có chút khiếu hài hước
Đó là vấn đề. Đó là bí mật bẩn thỉu của cả ngành. Dữ liệu độ dài thay đổi + tensor hình chữ nhật = GPU của bạn được trả tiền theo giờ để làm công việc giả tạo.
WarpGroup-Backend là kết quả khi bạn quyết định "đủ rồi", và bạn thà viết 30% C++ còn hơn cứ phải trả tiền cho sự lãng phí đó.
2. Tại sao việc đệm (padding) lại tồn tại?
GPU thích hình chữ nhật. Cụ thể, nó thích các ma trận trong đó mỗi hàng có cùng độ dài, vì điều đó cho phép nó chạy hàng nghìn phép tính toán giống hệt nhau song song. Nhưng văn bản không phải là hình chữ nhật; nó là một mớ hỗn độn lắt nhắt. Một tweet có 12 token, một hợp đồng pháp lý có 4.000 token.
Bạn có hai lựa chọn:
- Đệm tất cả đến cái dài nhất bằng một token đặc biệt (cách mặc định của HuggingFace). Toán học chạy trên hình chữ nhật, code của bạn đơn giản, nhưng GPU giờ dành phần lớn thời gian để nhân 0 với 0.
- Nối chúng thành một dải 1-D dài và nói với kernel chú ý rằng "này, đừng để token 12 nói chuyện với token 4001 nhé, chúng từ不同的 tài liệu đấy". Đây là biến dài chú ý (variable-length attention), những gì
flash_attn_varlen_funccủa FlashAttention-2 làm.
Lựa chọn 2 rõ ràng tốt hơn. WarpGroup-Backend là phần "người tổ chức khó tính" của phương trình này, được viết bằng C++ để nó thực hiện nhanh chóng.
3. Đèn ý tưởng "chỉ cần đóng gói chúng vào" (và tại sao nó khó hơn nghe)
Ý tưởng rất đơn giản: lấy hàng đợi các chuỗi độ dài thay đổi và đóng gói chúng vào các thùng (bins) như một bà cụ chuyển nhà cường điệu. Mỗi thùng chứa tối đa N token. Bạn nhồi nhiều chuỗi nhỏ vừa vặn bên cạnh chuỗi lớn, sau đó gửi cả thùng đến GPU dưới dạng một dải phẳng.
Đây là bài toán kinh điển bin-packing, và giải pháp sách giáo khoa là First-Fit Decreasing (FFD): Sắp xếp chuỗi từ dài đến ngắn, sau đó nhét vào thùng đầu tiên còn chỗ. Nó không tối ưu tuyệt đối, nhưng khá tốt.
Tuy nhiên, có ba vấn đề làm cho việc này không chỉ là một script Python 10 dòng:
- Vấn đề A: Thùng nên lớn thế nào? Bạn phải đo đạc nó (thử cho đến khi GPU báo OOM).
- Vấn đề B: GPU kén chọn (vấn đề 16-token). NVIDIA Tensor Cores hoạt động hiệu quả nhất khi kích thước là bội số của 16. Vì vậy, chúng ta làm tròn độ dài chuỗi lên: 137 → 144.
- Vấn đề C: Python quá chậm để làm việc này trong vòng lặp chính. Giải pháp: Đóng gói trong C++, trong luồng nền (background thread), và giải phóng GIL.
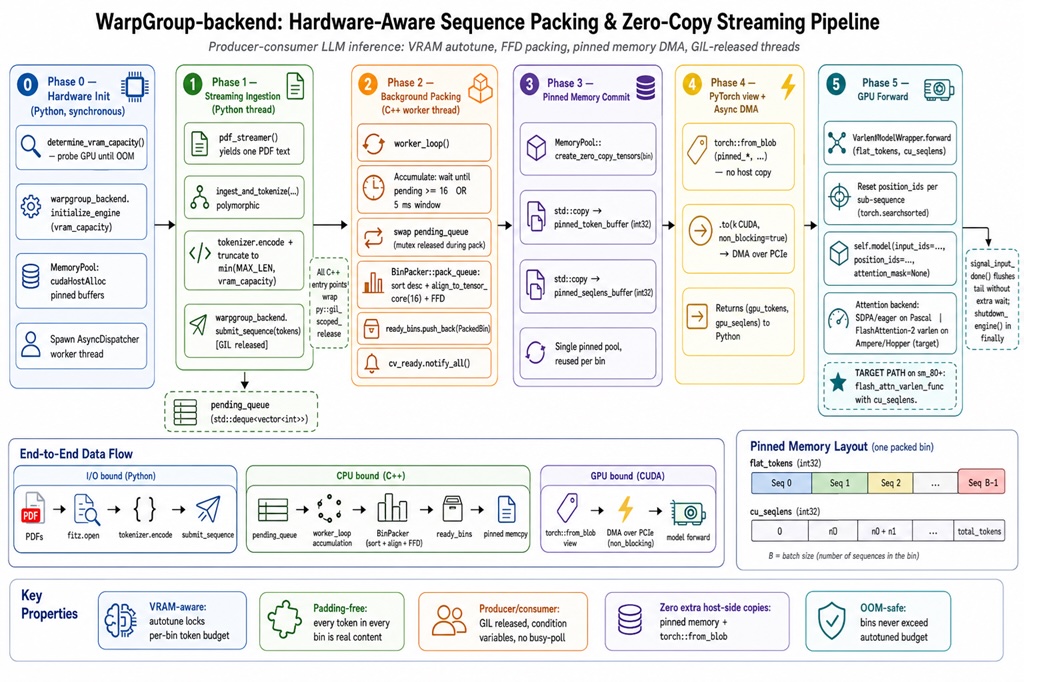
4. Pipeline năm giai đoạn
Đây là kiến trúc tổng thể:
- Phase 0: Đo lượng VRAM còn lại một cách thực nghiệm.
- Phase 1: Token hóa văn bản và chuyển số nguyên sang biên giới C++.
- Phase 2: Bắt đầu chúng trong hàng đợi an toàn luồng mà không có drama GIL.
- Phase 3: Sắp xếp, căn chỉnh và xếp chúng vào các thùng 1-D ( thuật toán Tetris).
- Phase 4: Đưa thùng cho GPU thông qua DMA bộ nhớ ghim bất đồng bộ.
- Phase 5: FlashAttention-2 tận hưởng bữa trưa không đệm.
Chi tiết quan trọng: Bộ nhớ ghim (Pinned Memory)
Chúng ta cần dữ liệu trên GPU. Cách tiếp cận ngây là memcpy vào tensor PyTorch rồi .to('cuda'). Tuy nhiên, thủ thuật là bộ nhớ ghim (page-locked host memory), được cấp phát qua cudaHostAlloc. Đây là RAM mà hệ điều hành bị cấm hoán đổi. Vì địa chỉ ổn định, DMA engine của GPU có thể kéo byte qua bus PCIe trong một lần truyền bất đồng bộ mà không cần CPU staging bản sao trung gian.
5. Kết quả (Các con số)
Thử nghiệm căng thẳng trên H100 với Qwen2.5–7B và 400 PDF độ dài hỗn hợp:
- Chi phí đệm: Giảm từ 48,41% xuống 0,55%.
- Tốc độ xử lý (Throughput): Tăng từ 14,713 tok/s lên 30,672 tok/s (tăng 2,08×).
- VRAM tối đa: Giảm 17% (tiết kiệm 3,38 GB).
Thử nghiệm trên phần cứng phổ thông: GTX 1080 (8 GB) với SmolLM2–360M:
- Tốc độ xử lý: Tăng từ 405 tok/s lên 2,387 tok/s (tăng 5,89×).
- VRAM tối đa: Giảm 35%.
Đây là phần yêu thích của tôi. Phần cứng càng nhỏ, việc đệm càng gây hại. Một GTX 1080 nhanh hơn gấp 5,89 lần có nghĩa là các startup nhỏ, phòng lab đại học, hoặc bất kỳ ai chạy trên một thẻ người dùng tiêu dùng vừa nhận được một bản nâng cấp phần cứng miễn phí.
6. Sự khác biệt với vLLM / TensorRT-LLM?
Một câu hỏi hợp lý. vLLM / continuous batching được tối ưu hóa cho serving thời gian giải mã (decode-time serving): nhiều yêu cầu đồng thời ở các bước tạo khác nhau. Nguyên thủy tiêu đề của nó là paged attention — một trình quản lý bộ nhớ KV-cache.
WarpGroup-Backend nhắm vào nửa kia của quang phổ khối lượng công việc: tác vụ xử lý lô ngoại tuyến / băng thông cao (offline/high-throughput). Đánh giá tài liệu, lập chỉ mục RAG, trích xuất embedding theo lô. Đơn vị công việc là kho tài liệu hữu hạn, không phải luồng yêu cầu giải mã liên tục. Hãy nghĩ thế này: vLLM là người quản lý nhà hàng sắp xếp thực khách đến bàn trong thời gian thực, còn WarpGroup là hoạt động cung cấp suất ăn trưa đóng hộp cho các xe tải giao hàng trước khi rời khỏi bến.
7. Một góc nhìn từ viễn thông (Cái Twist)
Tôi thú nhận rằng tôi không phải là người chuyên về GPU. Tôi đến từ lĩnh vực viễn thông — 5G NR — và tôi bắt đầu nhìn vào cơ sở hạ tầng suy luận LLM vì mọi vấn đề trong codebase này đều cảm thấy bất ngờ quen thuộc.
Hãy nhìn lịch trình bộ điều khiển MAC 5G (tại gNB) và so sánh với WarpGroup:
- Gói các SDU kích thước biến đổi vào Khối Giao vận (Transport Block) vs. Đóng gói chuỗi token vào thùng VRAM.
- Phải căn chỉnh theo đoạn khối mã LDPC vs. Phải căn chỉnh theo ô Tensor Core 16-token.
- Giới hạn bởi PRBs sẵn có vs. Giới hạn bởi ngân sách VRAM thực nghiệm.
Đây là cùng một thuật toán. Bộ điều khiển MAC tại trạm gốc đã đóng gói các payload kích thước biến đổi vào các khối có ngân sách cố định kể từ thời LTE-Advanced. Điều duy nhất thay đổi trong WarpGroup là đơn vị (token thay vì bit) và ngân sách (VRAM thay vì PRBs).
Kết luận
Có ba bài học rút ra:
- Việc chạy lô mặc định là một lời nói dối lịch sự.
batch_size = 8không cho bạn biết GPU đã đầy bao nhiêu. Đơn vị đúng là token trong VRAM. - Công việc hiệu suất thú vị nằm ở các ranh giới: tokens-to-tensors, host-to-device, Python-to-C++.
- Đôi khi câu trả lời đúng là "viết C++". Di chuyển vòng lặp đóng gói nóng vào luồng nền C++ giúp loại bỏ sự tranh giành GIL và chi phí của trình thông dịch.
Đệm là khoản thuế thầm lặng trên mọi khối lượng công việc LLM liên quan đến văn bản độ dài thay đổi. Nếu bạn xây dựng cơ sở hạ tầng suy luận LLM, hãy cân nhắc xem bao nhiêu pipeline của bạn hiện đang trả "thuế đệm" này.
Bài viết liên quan

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
Công nghệ
Giải mã cơ chế vận hành của đồng hồ cơ học: Sự giao thoa giữa nghệ thuật và kỹ thuật
16 tháng 6, 2026

Công nghệ
tvOS 27 vắng bóng tại WWDC 2026: Apple đang chờ đợi phần cứng mới?
08 tháng 6, 2026