
Tối ưu hóa Chi phí Token: Biến Agentic AI từ Nguyên mẫu thành Sản phẩm Lợi nhuận
Bài viết phân tích chuyển dịch trọng tâm từ khả năng kỹ thuật sang hiệu quả chi phí trong phát triển ứng dụng Agentic AI. Tác giả đề xuất các giải pháp kiến trúc như "Cam kết sớm" (Early Commitment) và "Tái phát hành xác định" (Deterministic Replay) để giảm thiểu lãng phí token mà vẫn duy trì khả năng thích ứng của hệ thống.
Chúng ta đã chính thức vượt qua giai đoạn tạo nguyên mẫu AI. Tiếp nối các khái niệm trong "Escaping the Prototype Mirage", các đội ngũ sản phẩm và kỹ thuật trên mọi lĩnh vực hiện đang đưa ra các ứng dụng dạng tác nhân (agentic applications) giải quyết các quy trình làm việc trước đây chủ yếu do con người thực hiện thủ công.
Việc xây dựng các nguyên mẫu cho các tác nhân tự chủ này hiện nay trở nên dễ dàng dàng. Nó đơn giản như việc sử dụng các khái niệm chính như "Vòng lặp Agentic đệ quy" (Observe-Think-Act) để thực thi, thiết lập các cổng vô hình (headless gateways) để kết nối các tác nhân qua ứng dụng chat, và dựa vào trạng thái được lưu trữ duy trì qua các lần khởi động lại. Tuy nhiên, việc đưa chúng trở thành các sản phẩm đáng tin cậy là một câu chuyện khác. Biên giới mới không còn là chứng minh tác nhân có thể làm việc, mà là chứng minh chúng có thể làm việc có lãi.
Đồng thời, các chỉ số nội bộ tại các doanh nghiệp như "tối đa hóa token" (sử dụng token không giới hạn để đạt kết quả tốt nhất) vốn phù hợp với giai đoạn nguyên mẫu đang chuyển sang đo lường tỷ lệ "giá trị trên số token đã tiêu thụ" khi các sản phẩm agentic mở rộng quy mô. Phần lớn các sản phẩm cần có lợi nhuận và tối đa hóa biên lợi nhuận khi chúng chuyển từ việc sử dụng máy tính truyền thống giá rẻ (TradCompute) sang sử dụng trí tuệ AI.
Tuy nhiên, các mô hình cần sự tự do suy luận và các nghiên cứu gần đây cho thấy các quy trình làm việc agentic mang tính khám phá vượt trội hơn so với các đường dẫn cố định. Điều này đặt ra câu hỏi về việc cân bằng nhu cầu tự chủ của mô hình với thực tế kinh tế của chi phí suy luận (inference costs).
Tại sao các Tác nhân Bị Giới hạn Thất bại trong Đưa ra Kết luận
Các hệ thống điều khiển tác nhân (agent harnesses) lưu trữ ngữ cảnh nhiệm vụ và mục tiêu của bạn trong các tệp markdown (*.md), những tệp này thường không đại diện cho các quy trình làm việc chặt chẽ, mà phác thảo ý định hoặc mục tiêu bạn muốn đạt được.
Nghịch lý của Thất bại Mục tiêu: Trong các nghiên cứu về tác nhân giải quyết các vấn đề phức tạp, các nhà nghiên cứu phát hiện ra rằng việc cung cấp các hướng dẫn nghiêm ngặt, bị giới hạn cao, trong đó mỗi hành động của tác nhân đưa nó đến gần hơn với mục tiêu, dẫn đến việc bị mắc kẹt ở điểm tối ưu cục bộ (local optima) và gây ra thất bại về mục tiêu.
Một ví dụ từ nghiên cứu của Giáo sư Jeff Clune về học tập mở-ended cho tác nhân minh họa điều này hoàn hảo: một tác nhân trong mê cung, khi liên tục được thưởng chỉ đơn thuần vì tìm đường trực tiếp ra lối thoát, sẽ liên tục đâm vào tường và bị mắc kẹt ở điểm tối ưu cục bộ, không bao giờ đến được đích.
Sức mạnh của Hệ thống Điều khiển Không Giới hạn: Các hệ thống điều khiển tác nhân đương đại như Google Antigravity và Claude Code của Anthropic rất hiệu quả vì chúng cho phép các tác nhân tạo ra, điều phối, thực hiện các tác vụ phức tạp, thậm chí tạo ra công cụ riêng của chúng mà không cần sự quản lý vi mô nghiêm ngặt của con người. Chúng thành công vì được trao tự do khám phá các đường đi vòng vo.
Hãy xem xét một trường hợp ngoại lệ trong quy trình nhập khám y tế thông thường: nếu chúng ta giới hạn một tác nhân y tế chặt chẽ chỉ để theo luồng đặt lịch được xác định trước, nó sẽ bị phá vỡ trong thế giới thực. Nếu bệnh nhân đề cập đến đau ngực giữa chừng nhập khám thông thường, vòng lặp Agentic của tác nhân phải có quyền tự chủ để nhận ra ngay lập tức tính cấp bách, bỏ qua luồng đặt lịch và kích hoạt quy trình thang độ an toàn. Nó nên sử dụng cái mà chúng ta previously gọi là No-Reply Token để chặn các cuộc trò chuyện đặt lịch và định tuyến ngữ cảnh trực tiếp cho y tá chuyên khoa.
Việc Tìm kiếm Mục tiêu Vô hạn là Đắt đỏ
Mặc dù cung cấp quyền tự chủ là rất cần thiết để khám phá giải pháp ban đầu, việc chạy một tìm kiếm mở-ended hoàn chỉnh cho mọi yêu cầu quy trình làm việc của người dùng có thể dẫn đến việc tiêu thụ token lớn một cách không bền vững. Ở giai đoạn này, tác nhân đã tìm thấy một đường đi hợp lệ và cách tiếp cận này vốn dĩ cho phép nó khám phá lại hoặc "ảo giác" cấu trúc quy trình làm việc.
Ví dụ, định tuyến các quy trình nhập khám y tế và thậm chí cả các trường hợp ngoại lệ cần nâng cấp có thể được học hỏi theo thời gian. Các quy trình của một phòng khám hoặc nhà cung cấp giải pháp sẽ chuyển thành các đường dẫn xác định (deterministic paths) phần lớn, để lại một số quyền tự chủ được dành riêng cho các trường hợp ngoại lệ hiếm gặp và phức tạp.
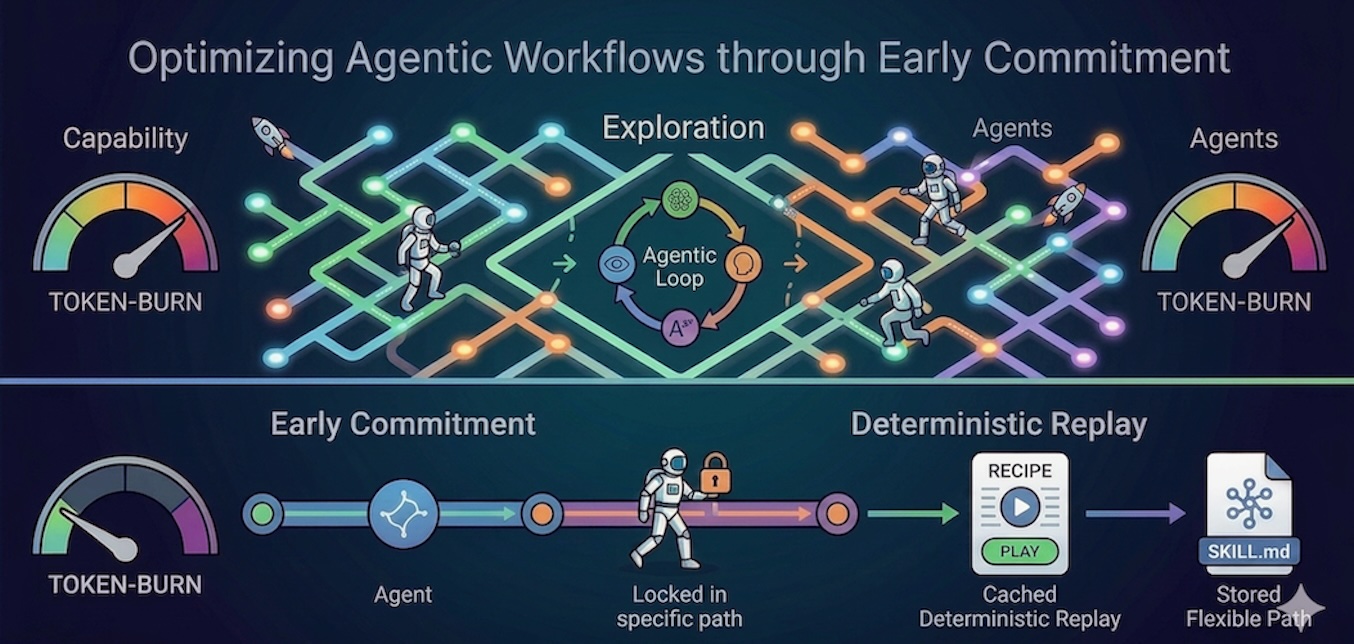
Giải pháp Kiến trúc thông qua Cam kết Sớm và Tái phát hành Xác định
"Cam kết Sớm" (Early Commitment) đã cho thấy triển vọng trong giải quyết vấn đề có cấu trúc và nó cũng có thể được áp dụng cho các quy trình làm việc agentic. Nó liên quan đến việc phân loại vấn đề trước, ví dụ bằng cách cấu trúc hệ thống yêu cầu mô hình xuất ra một thẻ phân loại cụ thể. Bằng cách buộc một tác nhân phân loại loại vấn đề và thiết lập các ràng buộc trước khi nó tạo ra logic thực thi, bạn ngăn chặn tác nhân ảo giác hoặc khám phá các đường cùng cụt.
Ví dụ, trong quy trình sàng lọc telehealth, chúng ta có thể thực thi Cam kết Sớm bằng cách yêu cầu tác nhân phân loại chính xác cuộc gặp là "đơn thuốc thường" trước khi thực hiện bất kỳ hành động nào. Khi đã cam kết với ràng buộc cụ thể này, tác nhân hạn chế các cuộc gọi công cụ (tool calls) của mình nghiêm ngặt vào cơ sở dữ liệu nhà thuốc, hoàn toàn bỏ qua các đường dẫn suy luận chẩn đoán tốn kém và mở-ended mà nó có thể đi lạc vào.
Một nghiên cứu gần đây của Wang, X., và cộng sự giới thiệu khung LOOP Skill Engine, đưa cam kết sớm lên cấp độ hạ tầng bằng cách sử dụng mô hình ghi một lần và tái phát hành xác định (deterministic replay). Tác nhân có thể tự chủ khám phá một lần sử dụng suy luận đầy đủ, và sau đó hệ thống biên dịch dấu vết thành công đó thành một công thức không có nhánh. Đối với tất cả các lần chạy trong tương lai, LLM có thể được bỏ qua, đảm bảo tính xác định trong thực thi và giảm thiểu việc sử dụng token hơn 93,3% cho các tác vụ hàng ngày, và lên tới 99,98% cho các lần thực thi tần suất cao.
Hãy xem xét việc tạo báo cáo tuân thủ phòng khám hàng ngày hoặc tóm tắt xuất viện tiêu chuẩn, là những nhiệm vụ ổn định và lặp đi lặp lại cao. Bắt đầu từ việc khám phá và sau đó nhanh chóng chuyển sang một khuôn khổ xác định, một tác nhân chỉ phải suy luận qua việc trích xuất dữ liệu phức tạp từ Hồ sơ Sức khỏe Điện tử (EHR) chính xác một lần. Đối với 100 bệnh nhân tiếp theo xuất viện với cùng quy trình, hệ thống thực thi chính xác công thức không có nhánh đó, đáng tin cậy thay đổi các dấu hiệu sinh tồn và ngày tháng của bệnh nhân mới mà không bao giờ gọi LLM. Điều này đảm bảo dữ liệu bị ảo giác bằng zero trên các nhiệm vụ y tế lặp lại trong khi tối đa hóa hiệu quả token.
Các chuyên gia ML cần cân nhắc giữa việc tái phát hành xác định thuần túy (như LOOP) tối đa hóa việc tiết kiệm token, và cách tiếp cận lai (lưu đường dẫn đã khám phá trong tệp SKILL.md). Cách tiếp cận lai đánh đổi một phần tiết kiệm token đó để đổi lấy việc suy luận qua một đường dẫn được hướng dẫn tối ưu cao, nhưng vẫn để lại đủ linh hoạt để tự thích nghi với một khuôn khổ cơ bản thay đổi.
Kết luận: Quy trình ML Khám phá - Cam kết - Đo lường
Các kỹ sư ML và Quản lý Sản phẩm phải thích ứng ứng dụng của mình để tận dụng trí tuệ khổng lồ của các tác nhân tự chủ và đón nhận các hệ thống điều khiển không giới hạn cho việc khám phá vấn đề ban đầu và các trường hợp ngoại lệ phức tạp, duy nhất. Điều này mang lại các giải pháp tối ưu mà không cần chạy một chu kỳ học tập tăng cường đắt đỏ.
Khi chúng ta đã tìm thấy một đường đi gần tối ưu, kinh tế token đối với các nhiệm vụ có cấu trúc và lặp lại yêu cầu chúng ta thực thi cam kết sớm trong thiết kế lời nhắc (prompt), sử dụng các kiến trúc tái phát hành xác định để lưu bộ nhớ đệm đường dẫn thực thi.
Khi các sản phẩm agentic mở rộng quy mô, chúng ta phải chuyển các chỉ số vận hành từ tỷ lệ thành công nhiệm vụ đơn giản sang hiệu quả token và giá trị trên mỗi token được tạo ra.
Bài viết liên quan

Công nghệ
Camp Snap 2: Máy ảnh kỹ thuật số không màn hình mỏng hơn, thêm nhiều bộ lọc và màu sắc trong suốt
02 tháng 6, 2026

Công nghệ
Bị AI từ chối hồ sơ xin việc? Cuộc chiến đơn độc của một sinh viên y khoa
05 tháng 5, 2026
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026