
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
Bài viết này hướng dẫn cách kết hợp sức mạnh của Large Language Models (LLM) với các thuật toán lọc truyền thống để xây dựng hệ thống gợi ý hiệu quả. Bằng cách sử dụng kiến trúc phễu hai giai đoạn, chúng ta có thể giảm chi phí tính toán mà vẫn đảm bảo độ chính xác cao cho người dùng.

Có một câu nói nổi tiếng trong văn hóa Mỹ mà tôi rất thích: "Bạn không thể vừa có bánh vừa ăn bánh".
Tôi thấy câu này vừa mang tính thơ ca, vừa thực tế và hữu ích. Thông điệp của nó rất đơn giản: mọi thành tựu bạn đạt được đều đi kèm với sự đánh đổi, vì mọi thứ đều có cái giá của nó. Trong kỹ thuật phần mềm và khoa học dữ liệu, không có cái gọi là "thiết kế hoàn hảo" theo nghĩa đen. Cùng một thuật toán có thể tuyệt vời cho ứng dụng này nhưng lại thất bại thảm hại trong ứng dụng khác.
Hãy cùng xem xét sự đánh đổi giữa tính toán và bộ nhớ thông qua ví dụ về các mô hình ngôn ngữ lớn (LLM).
 Hệ thống gợi ý thông minh
Hệ thống gợi ý thông minh
LLM là những mô hình AI mạnh mẽ nhất hiện nay, được huấn luyện trên toàn bộ kiến thức của thế giới. Tuy nhiên, chúng cũng cực kỳ lớn và tốn kém. Chúng ta thường phải gọi chúng thông qua API, và mỗi lần gọi API đều đồng nghĩa với việc tiêu tốn token và chi phí.
Hãy tưởng tượng bạn muốn sử dụng một hệ thống thông minh để chọn nhà hàng tốt nhất cho tối nay. Bạn sẽ hỏi ChatGPT điều gì đó như: "Tôi muốn tìm một nhà hàng Ý, không quá đắt nhưng phải lãng mạn và ở vị trí thuận lợi".
Nếu mô hình GPT phải khám phá tất cả các nhà hàng trong vũ trụ để quyết định xem chúng có phải là Ý, không đắt, ở vị trí tốt và gần bạn hay không, thì kịch bản tốt nhất là bạn sẽ tiêu tốn hàng triệu token, và đến khi tính toán xong thì bạn đã đi ngủ từ lâu.
Tuy nhiên, chúng ta cũng không muốn từ bỏ hoàn toàn khả năng diễn giải ngôn ngữ tự nhiên và truy xuất thông tin mạnh mẽ của LLM. Chìa khóa nằm ở chỗ: để sử dụng LLM và nhận được thông tin thông minh, chúng ta không thể sử dụng phần thông minh nhất của quy trình mọi lúc. Trong bài viết này, tôi sẽ chia sẻ một công thức để xây dựng các hệ thống gợi ý được cải thiện bởi LLM, lấy ví dụ về gợi ý nhà hàng.
Thiết kế hệ thống: Kiến trúc phễu hai giai đoạn
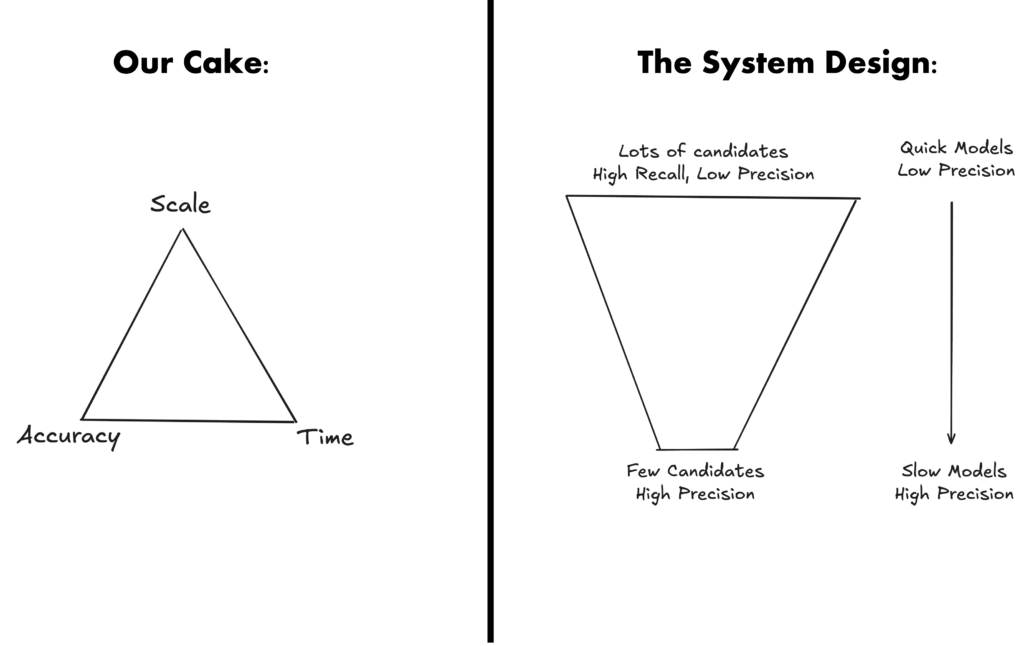
Câu nói về chiếc bánh cũng được biết đến trong kỹ thuật là "Tam giác Độ chính xác - Quy mô - Thời gian":
- Bạn có thể tạo ra một thứ chính xác và trên tập dữ liệu khổng lồ, nhưng nó sẽ chậm.
- Bạn có thể tạo ra một thứ chính xác và nhanh, nhưng nó không mở rộng tốt trên tập dữ liệu lớn.
- Bạn có thể tạo ra một thứ nhanh và mở rộng tốt, nhưng nó sẽ không quá chính xác.
Tất nhiên, chúng ta muốn kết quả của mình cuối cùng là chính xác, vì vậy chỉ chọn phương án 3 là không đủ. Tuy nhiên, chúng ta có thể tinh chỉnh phương án 3 với một mô hình chính xác hơn ở trên. Nói cách khác, phương án 3 có thể cung cấp cho chúng ta một danh sách ứng viên tốt với thời gian tính toán nhỏ, và chúng ta có thể chọn danh sách gợi ý chính xác nhất bằng cách sử dụng Large Language Model.
Thiết kế sẽ trông như sau:
- Một tìm kiếm nhanh và đơn giản sẽ tìm ra K nhà hàng gần nhất (dựa trên quy tắc, độ phủ cao, độ chính xác thấp).
- Một LLM chậm nhưng rất thông minh sẽ giúp chúng ta chọn ra cái tốt nhất trong số K ứng viên đó dựa trên truy vấn (dựa trên AI, độ chính xác cao).
 Sơ đồ thiết kế hệ thống
Sơ đồ thiết kế hệ thống
Bằng cách này, chúng ta không lãng phí thời gian và tiền bạc cho LLM chậm chạp, nhưng vẫn nhận được sự thông minh của chúng bằng cách sử dụng LLM trên một danh sách ứng viên đã được chọn lọc.
Triển khai với Python
1. Tạo dữ liệu giả lập
Trước khi có thể gợi ý bất cứ thứ gì, chúng ta cần dữ liệu. Trong một hệ thống thực tế, chúng ta sẽ sử dụng cơ sở dữ liệu nhà hàng. Đối với bài viết này, chúng ta sẽ tạo một bộ dữ liệu tổng hợp để mọi thứ có thể tái tạo hoàn toàn.
Chúng ta sẽ tạo một bảng có khoảng 10.000 nhà hàng rải rác trên tám thành phố lớn. Mỗi nhà hàng sẽ có tên, thành phố, vị trí địa lý, phong cách ẩm thực (Ý, Nhật Bản, Mexico...), chế độ ăn (thuần chay/ăn kiêng...), điểm đánh giá và mức giá.
2. Tạo danh sách ứng viên (Giai đoạn 1)
Đây là giai đoạn đầu của phễu: danh sách ứng viên dựa trên quy tắc, rẻ và nhanh. Người dùng cho chúng ta biết họ đang ở thành phố nào, và chúng ta chỉ giữ lại những nhà hàng ở gần về mặt địa lý.
Giai đoạn này được thiết kế để có độ phủ cao nhưng độ chính xác thấp. Với cách tiếp cận này, chúng ta có thể chạy trên toàn bộ bảng (10k nhà hàng) mà không cần một cuộc gọi API nào cả. Mục tiêu ở đây là lọc bỏ tất cả dữ liệu không khả thi cho người dùng.
Ví dụ, với yêu cầu: "tacos chay giá rẻ với không khí sống động", danh sách rút gọn ở giai đoạn này sẽ không biết gì về "chay", "rẻ" hay "tacos", nó chỉ biết về khoảng cách. Tuy nhiên, điều này ổn, vì mục tiêu là tạo ra một điểm khởi đầu phù hợp để LLM sắp xếp lại trong Giai đoạn 2.
3. Chọn lọc ứng viên bằng LLM (Giai đoạn 2)
Đây là giai đoạn cuối của phễu: chậm, thông minh, dựa trên LLM và có độ chính xác cao. Giai đoạn này xây dựng trực tiếp trên danh sách rút gọn 50 nhà hàng từ giai đoạn trước. LLM không bao giờ nhìn thấy bảng 10.000 hàng; nó chỉ nhìn thấy một phần nhỏ dữ liệu liên quan mà bộ lọc khoảng cách đã cung cấp.
Chúng ta sử dụng OpenAI client để giao tiếp với mô hình. Một điểm đáng chú ý là việc sử dụng Pydantic để đảm bảo đầu ra có cấu trúc. Mô hình bị buộc phải trả lời theo hình dạng của một mô hình Pydantic, do đó mọi phản hồi đều được đảm bảo khớp với lược đồ.
Kết quả trả về sẽ bao gồm restaurant_id, tên, fit_score (điểm phù hợp từ 0-100) và một lý do ngắn.
Kết quả
Hãy cùng xem xét những gì phễu hai giai đoạn mang lại cho chúng ta với cùng một yêu cầu: "tacos chay giá rẻ với không khí sống động".
Giai đoạn 1 cung cấp danh sách các nhà hàng gần nhất, bất kể yêu cầu cụ thể về món ăn hay chế độ ăn.
Giai đoạn 2 xác định các gợi ý thực sự. Việc đưa 50 ứng viên từ Giai đoạn 1 vào LLM sẽ sắp xếp lại chúng dựa trên những gì thực sự được yêu cầu.
Ví dụ, ở New York, các nhà hàng như "Golden Spoon" (chay) và "Maison Fork" (Mexico, trong ngân sách) sẽ nổi lên trên cùng với điểm phù hợp cao. Ở Miami, "Royal Tavern & Co." (chay, Mexico, giá cả phải chăng) dẫn đầu.
Trong mọi thành phố, mô hình đã ưu tiên các ứng viên khớp với ý định "chay, rẻ và Mexico/tacos", và trung thực về những sự phù hợp không hoàn hảo: những nơi đúng chế độ ăn nhưng sai món ăn (hoặc ngược lại) vẫn được giữ lại phương án dự phòng với điểm số thấp hơn rõ rệt.
Kết luận
Chúng ta đã cùng nhau xây dựng một phễu gợi ý hai giai đoạn vừa có khả năng mở rộng vừa thông minh. Chúng ta đã sử dụng bộ lọc khoảng cách dựa trên quy tắc (Giai đoạn 1) để cắt giảm 10.000 nhà hàng xuống còn 50 cái gần nhất. Sau đó, sử dụng việc xếp hạng lại bằng LLM (Giai đoạn 2) để biến 50 ứng viên đó thành 5-10 lựa chọn tốt nhất, kèm theo điểm số và lý do cụ thể.
Trong nhiều dự án thực tế, loại hệ thống phễu như thế này rất phổ biến vì nó tiết kiệm chi phí mà vẫn khai thác được khả năng hiểu ngữ cảnh tuyệt vời của các mô hình ngôn ngữ lớn.
Bài viết liên quan

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026