
Tối ưu hóa RAG: Chiến lược xử lý hình ảnh trong tài liệu kỹ thuật
Kapa.ai đã tìm ra giải pháp xử lý hàng triệu hình ảnh trong tài liệu kỹ thuật bằng cách chuyển đổi chúng thành mô tả văn bản tại thời điểm lập chỉ mục. Phương pháp này giúp giảm chi phí truy vấn và cải thiện độ chính xác mà không cần gửi hình ảnh gốc đến mô hình ngôn ngữ lớn (LLM).

Kapa.ai chuyên xây dựng các trợ lý AI trả lời câu hỏi từ tài liệu kỹ thuật. Các cơ sở kiến thức mà họ xử lý chứa hàng triệu hình ảnh: ảnh chụp màn hình, sơ đồ kiến trúc, mạch điện và hướng dẫn giao diện người dùng (UI). Thách thức đặt ra là làm thế nào để tận dụng nguồn tài nguyên này trong quy trình RAG (Retrieval-Augmented Generation) một cách hiệu quả.
 Hình ảnh minh họa quy trình xử lý
Hình ảnh minh họa quy trình xử lý
Thay vì gửi hình ảnh trực tiếp đến mô hình tại thời điểm truy vấn (query time), Kapa.ai chọn cách mô tả mỗi hình ảnh một lần duy nhất trong giai đoạn lập chỉ mục (indexing time) bằng một mô hình thị giác giá rẻ. Các mô tả này được lưu trữ dưới dạng văn bản và được truy xuất cùng với các đoạn văn bản thông thường. Chi phí lập chỉ mục chỉ phải trả một lần, sau đó chi phí cho mỗi truy vấn chỉ tăng từ 1% đến 6% so với chỉ xử lý văn bản, nhưng chất lượng câu trả lời được cải thiện một cách rõ rệt và có ý nghĩa thống kê.
Tại sao không xử lý hình ảnh tại thời điểm truy vấn?
Phương pháp tiếp cận phổ biến nhất là truy xuất các đoạn văn bản liên quan, thu thập hình ảnh được tham chiếu và gửi tất cả cho một mô hình có khả năng thị giác (vision-capable model). Tuy nhiên, Kapa.ai nhận thấy các vấn đề mang tính cấu trúc khi thử nghiệm với GPT-4.1 và Claude 3.5 Sonnet.
Về mặt kinh tế, việc thêm hình ảnh thô làm tăng 27% chi phí cho mỗi truy vấn trên GPT và 51% trên Claude. Với hàng triệu truy vấn, đây là một chi phí quá lớn khi phần lớn câu trả lời không cần phải nhìn lại các điểm ảnh của hình ảnh.
Hơn nữa, hình ảnh không vừa về mặt vật lý trong giới hạn tải trọng (payload limit). Một câu hỏi điển hình có thể truy xuất 20-30 hình ảnh, nhanh chóng chạm đến trần của Claude (30 MB) hoặc OpenAI (50 MB). Việc cắt giảm hình ảnh một cách quyết liệt sẽ làm mất đi mục đích của việc sử dụng chúng.
 Sơ đồ so sánh phương pháp tiếp cận
Sơ đồ so sánh phương pháp tiếp cận
Giải pháp: Mô tả hình ảnh tại thời điểm nhập liệu
Kapa.ai đã đảo ngược kinh tế học của vấn đề. Thay vì trả tiền để xử lý hình ảnh trên mọi truy vấn, họ trả tiền một lần tại thời gian lập chỉ mục để chuyển đổi mỗi hình ảnh thành một mô tả văn bản.
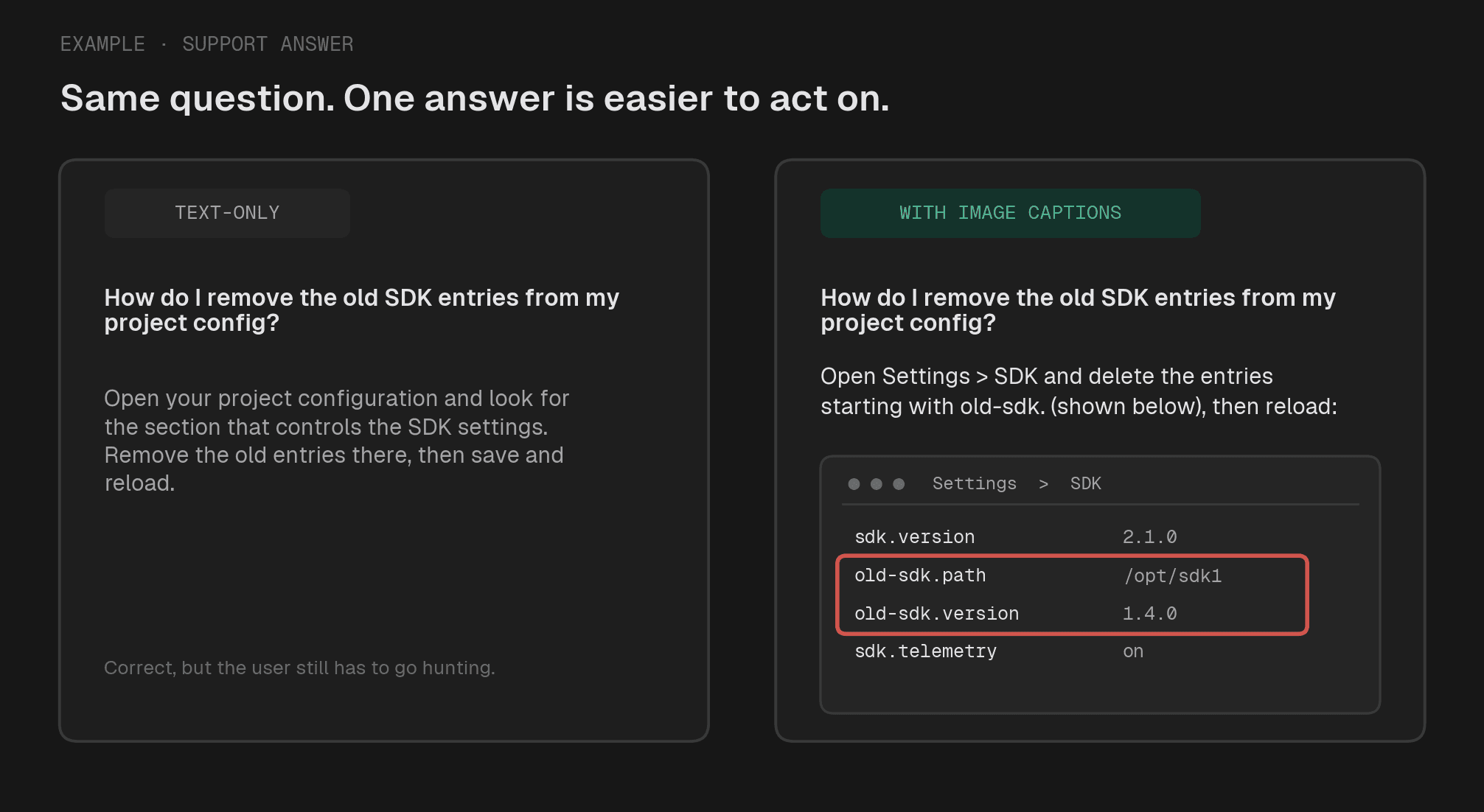
Tại thời điểm lập chỉ mục, một mô hình ngôn ngữ thị giác sẽ viết chú thích (caption) cho mỗi hình ảnh. Các chú thích này được lưu trữ và truy xuất cùng với các đoạn văn bản thông thường. Tại thời điểm truy vấn, nếu chú thích liên quan, bộ truy xuất sẽ kéo nó vào; mô hình sẽ thấy chú thích chứ không bao giờ thấy hình ảnh thô, và sẽ trích dẫn hình ảnh bằng URL gốc của nó.
Điều này hoạt động vì công việc nặng nề—thực sự nhìn vào hình ảnh—chỉ xảy ra một lần. Đối với ảnh chụp màn hình minh họa, chú thích là một mô tả; đối với hình ảnh mang tính chất "gánh nặng" (load-bearing) như bảng dữ liệu, chú thích là sự chuyển đổi những gì hình ảnh chứa đựng thành văn bản.
Phân loại và lọc nhiễu
Không phải mọi hình ảnh đều đáng để chú thích. Phần lớn là nhiễu: logo, ảnh đại diện, thẻ xem trước mạng xã hội, biểu ngữ trang trí. Các quy tắc heuristic xử lý đợt đầu (loại bỏ định dạng không được hỗ trợ, hình ảnh quá nhỏ, tỷ lệ khung hình cực đoan).
Đối với phần còn lại, họ xây dựng một bộ phân loại zero-shot trên các đa phương thức (multimodal embeddings). Nó đủ rẻ để chạy trên toàn bộ kho dữ liệu. Trên các hình ảnh rõ ràng, nó đạt độ chính xác 96,8%. Tuy nhiên, đối với các hình ảnh mơ hồ, độ chính xác giảm xuống 59,8% vì không có ngữ cảnh xung quanh. Do đó, họ chấp nhận việc loại bỏ rác rõ ràng và dung thứ cho các trường hợp ranh giới.
 Quy trình lọc và xử lý hình ảnh
Quy trình lọc và xử lý hình ảnh
Chiến lược lưu trữ và kết quả
Có hai cách để tích hợp chú thích: Inline (thay thế văn bản alt của hình ảnh trong tài liệu) hoặc Separate (lưu trữ mỗi chú thích như một đoạn riêng biệt).
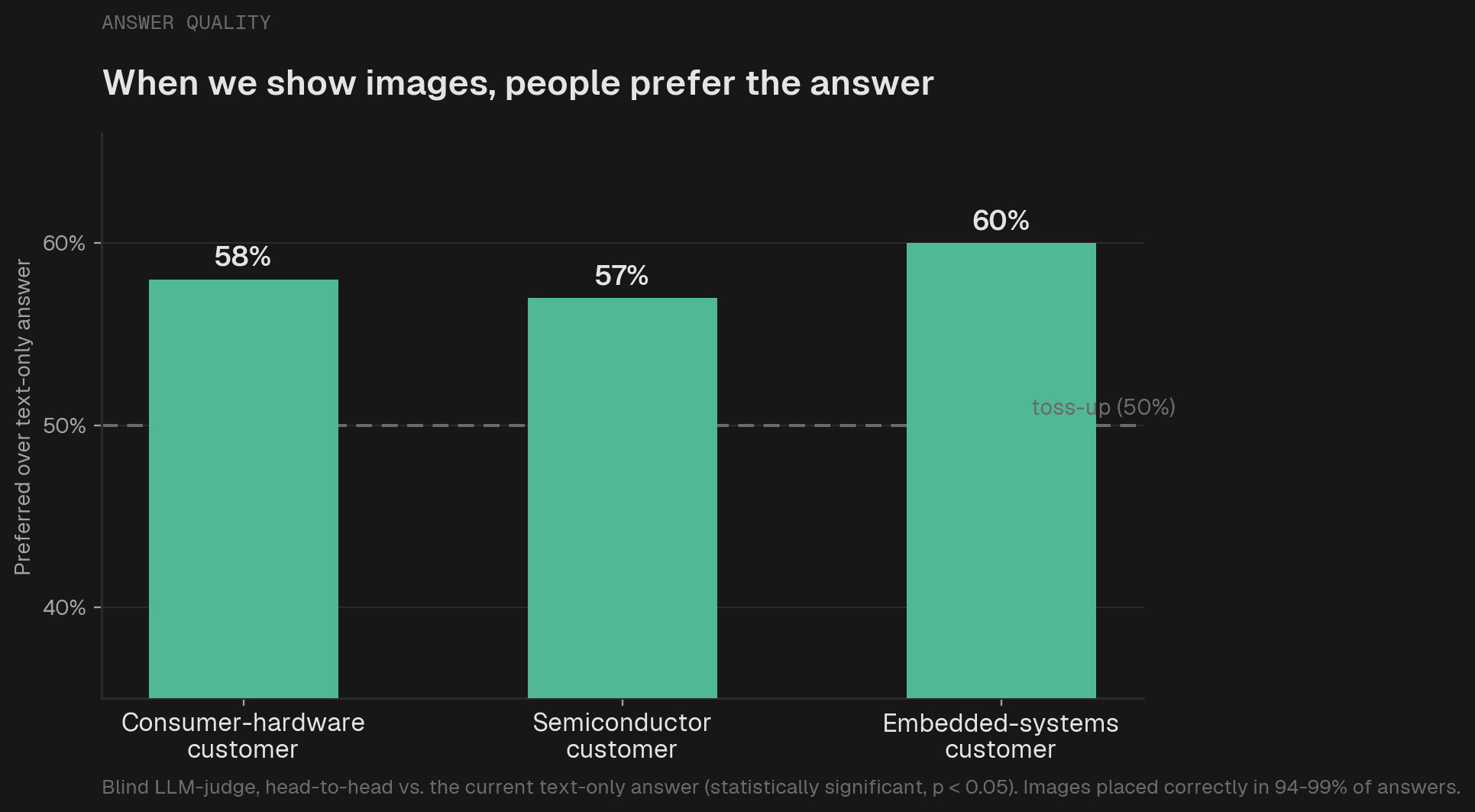
Kapa.ai nhận thấy phương pháp Separate chiến thắng về cả chi phí và mức độ sử dụng hình ảnh. Các đoạn chú thích riêng biệt chỉ đi vào ngữ cảnh khi bộ truy xuất đánh giá chúng là phù hợp, do đó bạn chỉ trả tiền cho hình ảnh khi nó thực sự quan trọng. Trên một dự án nhiều hình ảnh, phương pháp inline làm tăng chi phí truy vấn 19% với GPT, trong khi phương pháp separate chỉ tăng 6%.
Kết quả cuối cùng trên ba dự án khách hàng cho thấy hình ảnh được đặt đúng vị trí 94% đến 99% thời gian. Đây là một giải pháp ít "hào nhoáng" hơn việc "sử dụng mô hình đa phương thức", nhưng nó hiệu quả vì nó đặt khả năng thị giác vào đúng nơi: một lần duy nhất tại thời điểm nhập liệu.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026