
Từ Regex đến Vision Models: Chọn kỹ thuật RAG nào cho từng bài toán cụ thể
Bài viết này cung cấp một cái nhìn chẩn đoán về các kỹ thuật RAG trong doanh nghiệp, từ việc sử dụng Regex đơn giản đến các mô hình thị giác phức tạp. Thay vì áp dụng một quy trình chuẩn cho mọi trường hợp, tác giả đề xuất một lưới chẩn đoán dựa trên độ phức tạp của tài liệu và mức độ kiểm soát của câu hỏi để chọn giải pháp tối ưu nhất.

Hầu hết các vấn đề về RAG (Retrieval-Augmented Generation) không xứng đáng được giải quyết bằng một "sách lược kinh điển" duy nhất. Mọi đội ngũ phát triển hệ thống RAG thường có xu hướng áp dụng cùng một quy trình: phân tích tài liệu thành các đoạn (chunks), nhúng (embed) từng đoạn, lưu vào kho vector, nhúng câu hỏi, truy xuất top-k theo độ tương đồng cosine, rồi đưa kết quả cho một LLM xử lý. Đây là sách lược RAG kinh điển mà mọi hướng dẫn đều dạy.
Tuy nhiên, các vấn đề thực tế lại đa dạng hơn nhiều so với những gì sách lược này gợi ý. Bài viết này sẽ đóng vai trò như một công cụ chẩn đoán giúp bạn xác định kỹ thuật nào phù hợp nhất cho từng trường hợp cụ thể.
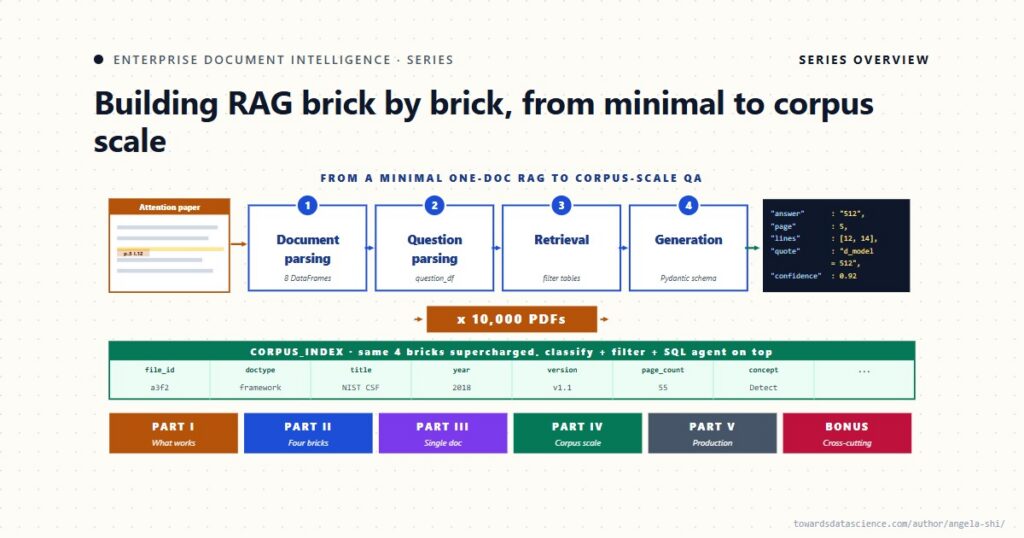 Tổng quan về RAG trong doanh nghiệp
Tổng quan về RAG trong doanh nghiệp
Ba trường hợp cực đoan
Để thấy rõ sự hạn chế của sách lược kinh điển, hãy xem xét ba trường hợp ở hai thái cực:
1. Tài liệu có khuôn mẫu cố định, khối lượng lớn Đây là các loại giấy tờ như chứng chỉ bảo hiểm, biểu mẫu KYC, hồ sơ pháp lý, sao kê môi giới hàng tháng. Cùng một phần mềm tạo ra cùng một bố cục trên mọi tài liệu. Một trăm dòng mã Regex có thể trích xuất các trường dữ liệu trong tích tắc. Sách lược kinh điển vẫn hoạt động ở đây, nhưng nó tốn kém chi phí LLM để làm những việc mà bố cục tài liệu đã cung cấp miễn phí.
2. Châm biếm trong bản ghi cuộc gọi hỗ trợ Nhiệm vụ: "Tìm mọi nhận xét châm biếm trong các bản ghi cuộc gọi tháng này". Điểm số tình cảm (sentiment scoring) tiêu chuẩn thường thất bại với châm biếm. Câu như "Ôi, dịch vụ tuyệt vời, chỉ phải đợi 45 phút thôi" sẽ được đánh giá tích cực vì từ ngữ bề mặt giống như lời khen chân thành. Phương pháp trung thực duy nhất là sử dụng LLM đọc toàn bộ cuộc gọi và phán đoán khoảng cách giữa những gì nói và những gì ý nghĩa thực sự.
3. Sơ đồ kỹ thuật Đây là các bản vẽ, slide trình bày nơi dữ liệu nằm trong biểu đồ, thông số kỹ thuật có hình ảnh nhúng. RAG chỉ dựa trên văn bản thuần sẽ chỉ trả về chú thích và bỏ lỡ sơ đồ. Các mô hình thị giác (Vision models) là giải pháp duy nhất ở đây.
Sách lược kinh điển là sự lãng phí đối với tài liệu có khuôn mẫu (Regex là đủ), sai lệch về mặt khái niệm đối với bản ghi thoại (không có neo văn bản), và "mù" phương thức đối với sơ đồ (cần thị giác). Nó chỉ phù hợp với một nhóm vấn đề ở giữa, nhưng lại được quảng bá như giải pháp cho mọi thứ.
Hai trục chẩn đoán: Độ phức tạp tài liệu và Kiểm soát câu hỏi
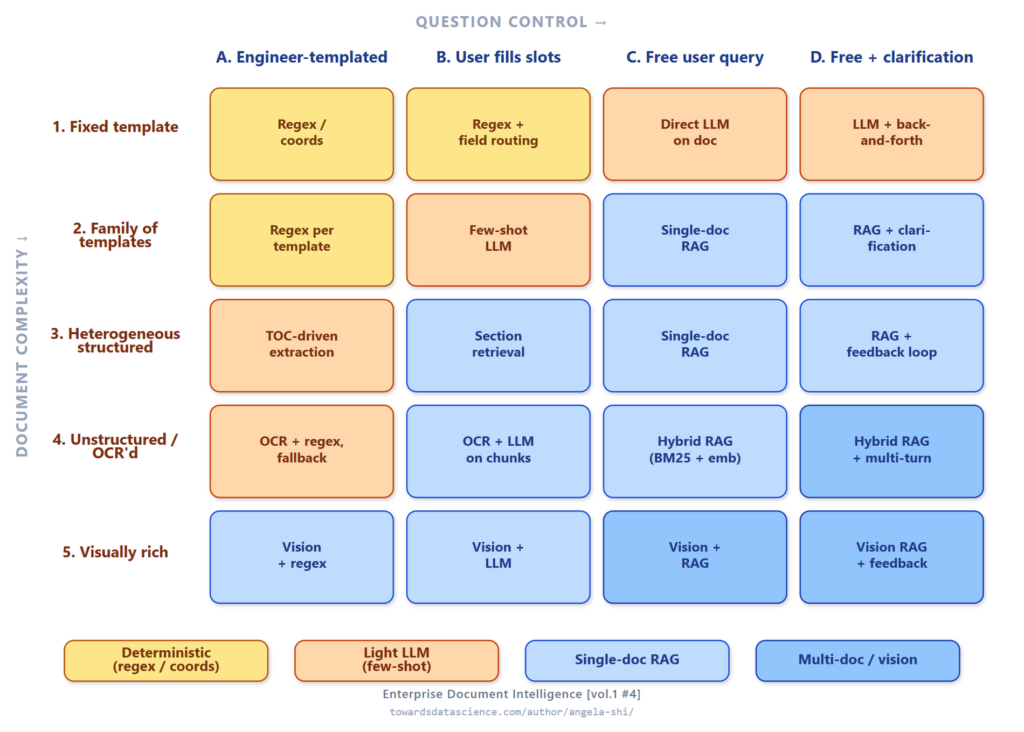
Vấn đề RAG không phải là một vấn đề đơn nhất. Nó nằm trên một hình ảnh với hai trục: tài liệu của bạn có cấu trúc như thế nào và câu hỏi của bạn được kiểm soát ra sao.
 Lưới chẩn đoán các trường hợp RAG
Lưới chẩn đoán các trường hợp RAG
Trục tài liệu: Từ khuôn mẫu cố định đến Vision Model
Chúng ta chia độ phức tạp của tài liệu thành 5 cấp độ:
- Cấp độ 1: Khuôn mẫu cố định. Mọi tài liệu có cùng cấu trúc, cùng trường ở cùng vị trí (ví dụ: chứng chỉ bảo hiểm từ một môi giới duy nhất). Kỹ thuật: Regex hoặc trích xuất dựa trên tọa độ, không cần mô hình.
- Cấp độ 2: Họ khuôn mẫu. Tài liệu tuân theo một mẫu nhận biết được nhưng có biến thể (ví dụ: hóa đơn từ nhiều nhà cung cấp khác nhau). Kỹ thuật: Regex cho từng mẫu cộng với LLM vài mẫu (few-shot) làm dự phòng khi mẫu thay đổi.
- Cấp độ 3: Cấu trúc dị biệt. Mỗi tài liệu có cấu trúc riêng (phần, tiêu đề, mục lục) nhưng không lặp lại (ví dụ: hợp đồng pháp lý tùy chỉnh). Kỹ thuật: phân tích cấu trúc, truy xuất qua mục lục của tài liệu.
- Cấp độ 4: Phi cấu trúc / OCR. PDF được quét, ảnh chụp giấy tờ, văn bản có nhưng bố cục bị suy giảm. Kỹ thuật: OCR với điểm tin cậy, sau đó là truy xuất kết hợp (lexical + embeddings) trên văn bản nhiễu.
- Cấp độ 5: Giàu tính thị giác. Ý nghĩa nằm ở hình ảnh: sơ đồ, bảng dữ liệu dày đặc nhúng dưới dạng ảnh. Kỹ thuật: Mô hình có khả năng thị giác trên ảnh trang, thường kết hợp với RAG phía văn bản.
Trục câu hỏi: Từ câu hỏi cố định đến Chatbot đa vòng
Trục này thường bị các đội ngũ bỏ qua, nhưng nó quyết định stack kỹ thuật cần dùng:
- Cấp độ A: Do kỹ sư tạo mẫu. Câu hỏi là tham số của hệ thống (ví dụ: "Trích xuất ngày hiệu lực"). Kỹ thuật: Trích xuất trường, đầu ra có cấu trúc.
- Cấp độ B: Người dùng điền vào chỗ trống. Câu hỏi là mẫu có giá trị do người dùng cung cấp (ví dụ: "Hiện thị điều khoản về {chủ đề}"). Kỹ thuật: Truy xuất phần, tra cứu theo danh mục đã biết.
- Cấp độ C: Truy vấn tự do, một lần. Người dùng nhập bất cứ gì họ muốn. Kỹ thuật: RAG tài liệu đơn với phân tích câu hỏi.
- Cấp độ D: Truy vấn tự do có làm rõ. Hệ thống có thể hỏi lại người dùng khi câu hỏi mơ hồ (ví dụ: "Ý bạn là trang 3 hay phụ lục 2?"). Kỹ thuật: Phân tích câu hỏi cộng với vòng lặp làm rõ.
Ánh xạ trường hợp đến kỹ thuật
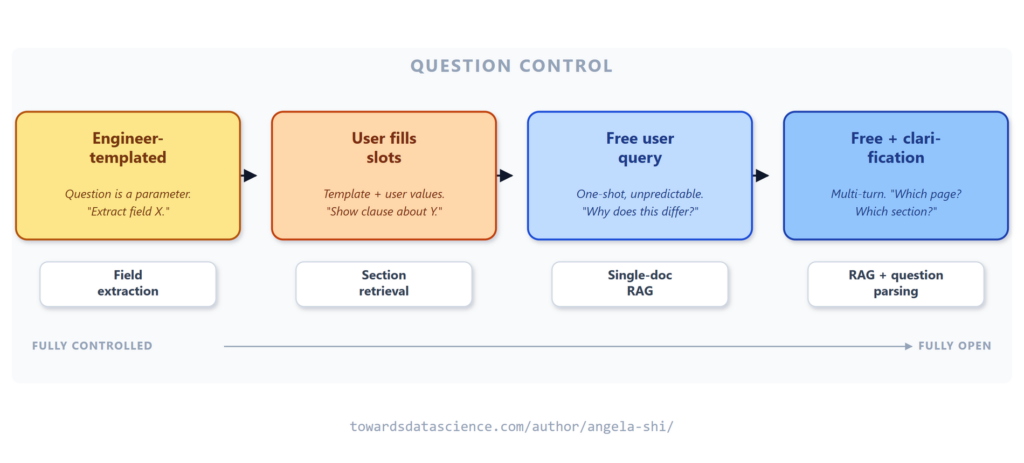
Khi giao hai trục này, mọi vấn đề RAG trên một file PDF sẽ rơi vào một vùng trên lưới. Mỗi vùng yêu cầu một stack kỹ thuật khác nhau.
 Các kỹ thuật cho từng trường hợp
Các kỹ thuật cho từng trường hợp
- Góc trên bên trái (Xác định): Khuôn mẫu cố định, câu hỏi được kiểm soát. Không cần LLM cho trích xuất trường; Regex là đủ. Đây là nơi hầu hết các quy trình tài liệu doanh nghiệp nằm, và thường bị thiết kế quá phức tạp (over-engineered).
- Dải giữa (RAG tài liệu đơn): Đây là trường hợp "chat với PDF" mà mọi demo nhà cung cấp đều show. Nó thật, nó khó, và cần các kỹ thuật như Chunking, Retrieval, Reranking.
- Dòng dưới cùng (Thị giác): Biểu đồ, sơ đồ. Trình phân tích văn bản sẽ mất câu trả lời bất kể truy xuất thông minh đến đâu. Cần Vision models.
Nguyên tắc cốt lõi
Chọn kỹ thuật đơn giản nhất hoạt động được
Bản năng của các đội ngũ kỹ thuật là xây dựng pipeline mạnh nhất có thể. Nhưng ở đây, bản năng đúng là chọn kỹ thuật yếu nhất giải quyết được vấn đề thực tế vì ba lý do: Chi phí (Regex rẻ hơn LLM rất nhiều), Độ trễ (tỷ giây so với giây), và Độ tin cậy (Regex hoặc khớp hoặc không, dễ kiểm toán).
Ngữ cảnh dài (Long Context) không phải là giải pháp thoát hiểm
Nhiều người cho rằng RAG đã chết vì cửa sổ ngữ cảnh (context window) ngày càng lớn. Tuy nhiên, việc ném toàn bộ tài liệu vào prompt không hiệu quả trong môi trường sản xuất vì lãng phí token, dễ bỏ sót thông tin ở giữa (vấn đề "Lost in the Middle"), không mở rộng được với kho lưu trữ lớn, và không có câu trả lời có cơ sở (grounded) để kiểm toán.
Các kỹ thuật "đắt tiền" thường là công việc từ khóa ngụy trang
Các kỹ thuật như HyDE (Hypothetical Document Embeddings) thường yêu cầu LLM viết một tài liệu giả định để truy xuất. Tuy nhiên, trong doanh nghiệp, các từ khóa chuyên ngành thường đã có trên trang. Một từ điển chuyên gia (Expert Dictionary) được xây dựng một lần với chuyên gia trong lĩnh vực sẽ làm được công việc tương tự với chi phí thấp hơn nhiều.
Kết luận
Hãy chạy chẩn đoán trên kho dữ liệu của bạn trước khi viết bất kỳ dòng mã nào. Các đội ngũ đưa RAG vào vận hành thành công là những đội ngũ định vị được vấn đề của họ trên lưới trước. Các đội ngũ vẫn đang điều chỉnh sau sáu tháng thường là những đội ngũ bắt đầu xây dựng mà không chẩn đoán trước.
Bài viết tiếp theo sẽ mở đầu Phần II với viên gạch đầu tiên: phân tích tài liệu. Mọi thứ bị mất ở bước đó đều không thể lấy lại sau này, bất kể truy xuất thông minh đến đâu.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026