
Tương quan và Nhân quả: Đo lường tác động thực tế với Propensity Score Matching
Propensity Score Matching (PSM) là kỹ thuật thống kê giúp phát hiện mối quan hệ nhân quả trong dữ liệu quan sát. Bằng cách tìm ra các "đôi sinh đôi" thống kê, phương pháp này loại bỏ thiên lệch lựa chọn để làm rõ tác động thực sự của các quyết định kinh doanh hoặc can thiệp.

So sánh các nhóm dữ liệu là một nhiệm vụ phổ biến trong Khoa học Dữ liệu (Data Science), đặc biệt khi chúng ta muốn thực hiện kiểm thử A/B để hiểu tác động của một biến số. Tuy nhiên, thế giới thực không phải lúc nào cũng là một môi trường thí nghiệm được kiểm soát hoàn hảo.
Thường thì sếp sẽ yêu cầu bạn đánh giá hiệu quả của chiến dịch mới dựa trên dữ liệu hiện có, mà bạn không hề chuẩn bị cho một thí nghiệm ngẫu nhiên từ trước. Đây chính là lúc Propensity Score Matching (PSM) trở nên hữu ích.
 Khái niệm Propensity Score Matching
Khái niệm Propensity Score Matching
PSM là gì?
Nói một cách đơn giản, PSM là một kỹ thuật thống kê được sử dụng để xác định xem một hành động cụ thể (một "điều trị") có thực sự gây ra kết quả hay không. Vì chúng ta không thể quay ngược thời gian để xem điều gì sẽ xảy ra nếu một người đưa ra quyết định khác, PSM giúp chúng ta tìm một "đôi sinh đôi" trong dữ liệu.
Chúng ta tìm một người có đặc điểm gần như giống hệt nhưng không thực hiện hành động đó, sau đó so sánh kết quả của họ. Việc tìm ra những "đôi sinh đôi thống kê" này giúp chúng ta so sánh khách hàng một cách công bằng, ngay cả khi không chạy một thí nghiệm ngẫu nhiên hoàn hảo.
Vấn đề của việc so sánh trung bình cộng
Việc so sánh trung bình cộng giả định rằng các nhóm ban đầu là giống hệt nhau. Tuy nhiên, khi so sánh nhóm đã được điều trị với nhóm kiểm soát, bạn đang vô tình đo lường tất cả các sự khác biệt vốn có khiến họ chọn hành động đó ngay từ đầu.
Hãy tưởng tượng chúng ta muốn thử nghiệm một loại gel năng lượng mới cho các vận động viên chạy bộ. Nếu chỉ so sánh những người dùng gel với những người không dùng, chúng ta đang bỏ qua các yếu tố quan trọng như kinh nghiệm và kiến thức của người chạy. Những người mua gel có thể đã có kinh nghiệm hơn, giày tốt hơn hoặc tập luyện chăm chỉ hơn. Họ vốn dĩ đã có xu hướng chạy nhanh hơn.
PSM thừa nhận những khác biệt này và hoạt động như một "trinh sát":
- Báo cáo trinh sát: Với mỗi vận động viên dùng gel, trinh sát xem xét chỉ số của họ: tuổi, năm kinh nghiệm và số dặm tập trung bình.
- Tìm kiếm người song sinh: Trinh sát tìm kiếm trong nhóm không dùng gel để tìm một "người song sinh" có chỉ số y hệt.
- So sánh: Bây giờ, bạn so sánh thời gian về đích của những "đôi song sinh" này.
 Quy trình tìm kiếm cặp dữ liệu tương đồng
Quy trình tìm kiếm cặp dữ liệu tương đồng
Nhờ đó, chúng ta so sánh các nhóm tương đồng: người chạy giỏi với người chạy giỏi, người chạy chậm với người chạy chậm. Điều này giúp cô lập các yếu tố gây nhiễu và đo lường tác động thực sự của gel năng lượng.
Các bước thực hiện PSM
Dưới đây là các bước logic để áp dụng PSM vào bất kỳ bộ dữ liệu nào:
- Tạo mô hình Hồi quy Logistic: Đây là mô hình phân loại nổi tiếng dự đoán xác suất một đối tượng có thể nằm trong nhóm điều trị hay không. Nói cách khác, đó là "xu hướng" (propensity) của cá nhân đó thực hiện hành động đang được nghiên cứu.
- Thêm điểm xu hướng: Thêm điểm xác suất tính được ở bước 1 vào bộ dữ liệu.
- Sử dụng thuật toán Nearest Neighbors: Quét nhóm kiểm soát để tìm người có điểm số gần nhất với mỗi người dùng được điều trị.
- Bộ lọc chất lượng (Caliper): Thêm một ngưỡng số để hiệu chuẩn. Nếu cặp khớp "gần nhất" vẫn vượt quá ngưỡng này, hãy loại bỏ chúng. Một mẫu nhỏ nhưng hoàn hảo tốt hơn một mẫu lớn nhưng thiên lệch.
- Đánh giá: Sử dụng Chênh lệch trung bình chuẩn hóa (Standardized Mean Difference - SMD) để kiểm tra xem hai nhóm có thực sự so sánh được hay không.
Triển khai với Python
Để minh họa, chúng ta sẽ sử dụng Python với các thư viện như pandas, sklearn và scipy.
Bước 1: Tính toán Propensity Scores
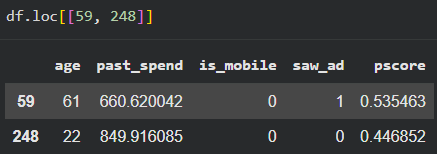
Chúng ta chạy mô hình LogisticRegression xem xét các biến như tuổi (age), chi tiêu trong quá khứ (past_spend) và việc sử dụng thiết bị di động (is_mobile) để ước tính xác suất một người nhìn thấy quảng cáo (saw_ad).
from sklearn.linear_model import LogisticRegression
covariates = ['age', 'past_spend', 'is_mobile']
treatment_col = 'saw_ad'
lr = LogisticRegression()
X = df[covariates]
y = df[treatment_col]
lr.fit(X, y)
df['pscore'] = lr.predict_proba(X)[:, 1]
Bước 2: Tìm các cặp khớp (Matching Pairs)
Sử dụng NearestNeighbors để tìm các cặp khớp. Chúng ta sử dụng cả pscore và age để đảm bảo sự tương đồng tốt nhất.
from sklearn.neighbors import NearestNeighbors
treated = df[df[treatment_col] == 1].copy()
control = df[df[treatment_col] == 0].copy()
caliper = 0.05
nn = NearestNeighbors(n_neighbors=1, radius=caliper)
nn.fit(control[['pscore', 'age']])
distances, indices = nn.kneighbors(treated[['pscore', 'age']])
Bước 3: Hiệu chỉnh mô hình
Chúng ta lọc ra các cặp khớp nằm ngoài ngưỡng caliper để đảm bảo chất lượng.
matched_control_idx = [control.index[i[0]] for d, i in zip(distances, indices) if d[0] < caliper]
matched_treated_idx = treated.index[:len(matched_control_idx)]
matched_control = control.loc[matched_control_idx]
matched_treated = treated.loc[matched_treated_idx]
matched_df = pd.concat([matched_treated, matched_control])
 Đánh giá kết quả mô hình
Đánh giá kết quả mô hình
Đánh giá kết quả
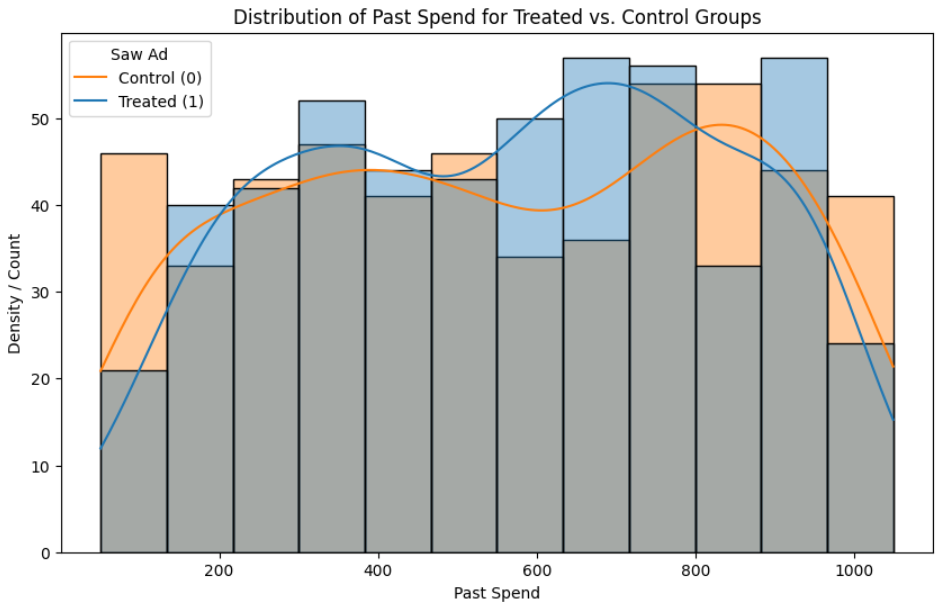
Sau khi khớp, chúng ta cần kiểm tra xem sự khác biệt về các biến số (ví dụ: past_spend) giữa hai nhóm có còn ý nghĩa thống kê hay không bằng cách sử dụng T-test và Cohen’s D.
Nếu kết quả cho thấy sự khác biệt không đáng kể (negligible effect), chúng ta có thể tin tưởng rằng mô hình đã loại bỏ được thiên lệch lựa chọn. Khi đó, sự khác biệt về kết quả đầu ra giữa hai nhóm sẽ phản ánh tác động thực sự của việc "nhìn thấy quảng cáo".
Kết luận
Tác động nhân quả (Causal Inference) là lĩnh vực của Khoa học Dữ liệu cung cấp cho chúng ta lý do tại sao một sự việc xảy ra, thay vì chỉ nói cho chúng ta biết liệu nó có khả năng xảy ra hay không.
Trong kinh doanh, việc hiểu rõ tại sao một chiến dịch thành công hay thất bại là vô cùng quý giá. PSM là một công cụ mạnh mẽ giúp bạn làm điều đó ngay cả khi dữ liệu không hoàn hảo. Hãy nhớ các bước cơ bản: chạy Hồi quy Logistic, chia nhóm, tìm khớp với Nearest Neighbors và đánh giá bằng SMD.
Bài viết liên quan

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026