
Vision LLM: Khi trình phân tích PDF biết "đọc" hình ảnh và biểu đồ cho hệ thống RAG
Các trình phân tích tài liệu truyền thống thường "mù" trước hình ảnh và biểu đồ. Bài viết này khám phá cách sử dụng Vision LLM để biến nội dung thị giác thành văn bản có thể tìm kiếm, mở rộng khả năng của hệ thống RAG doanh nghiệp.

Vision LLM: Khi trình phân tích PDF biết "đọc" hình ảnh và biểu đồ cho hệ thống RAG
Trong chuỗi bài viết về Enterprise Document Intelligence (Trí tuệ tài liệu doanh nghiệp), chúng ta đã từng bàn về việc xây dựng một hệ thống RAG (Retrieval-Augmented Generation) từ những viên gạch cơ bản. Trước đây, chúng ta sử dụng PyMuPDF (fitz) để đọc các từ ngữ trên một trang giấy. Tuy nhiên, bài viết này sẽ giới thiệu một cách tiếp cận khác: thay thế động cơ phân tích bằng một Vision LLM (Mô hình ngôn ngữ thị giác).
Thay vì chỉ đọc văn bản, Vision LLM coi trang PDF là một hình ảnh. Điều này cho phép nó trích xuất từ ngữ và cung cấp một thứ mà các trình phân tích văn bản thuần túy không thể làm được: nội dung của các hình ảnh, biểu đồ và sơ đồ.
1. Điều mà chỉ có mô hình thị giác mới làm được: Biến hình ảnh thành dữ liệu tìm kiếm
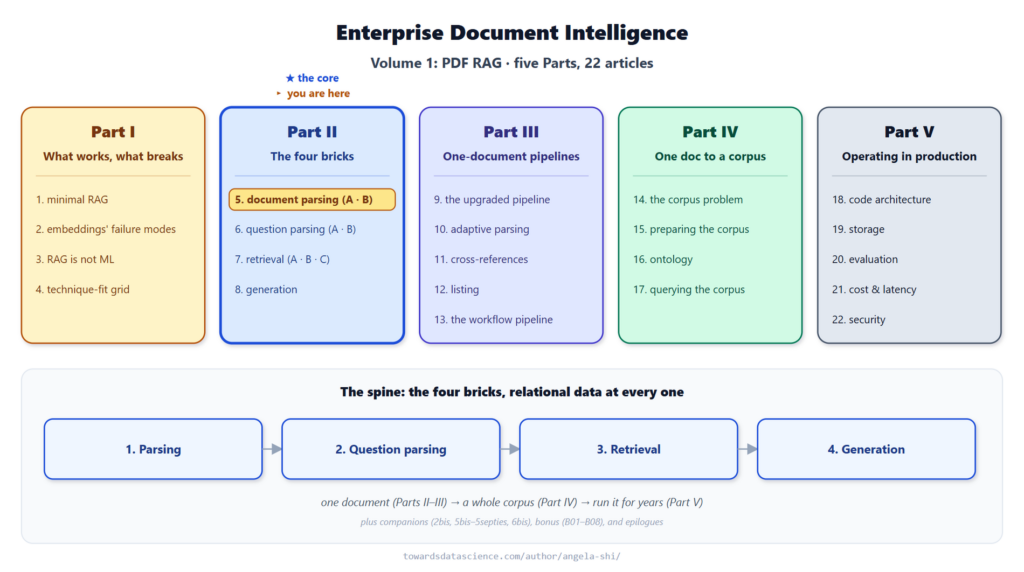
Hãy thử đưa một biểu đồ cho các trình phân tích PDF truyền thống, chúng sẽ chỉ nhìn thấy một hộp trống rỗng. Các động cơ văn bản, dù là native, trên đám mây hay cục bộ, đều chỉ tìm thấy chữ và đưa chúng vào bảng tìm kiếm. Vì biểu đồ không có chữ (hoặc rất ít), vùng đó bị coi là trống và không tồn tại đối với hệ thống truy xuất.
Vision LLM hoạt động khác biệt. Nó nhìn trang giấy giống như cách một con người nhìn.
 So sánh giữa OCR/Layout và Vision Parser
So sánh giữa OCR/Layout và Vision Parser
Hãy yêu cầu nó cung cấp văn bản, nó sẽ trả lời văn bản và bảng tính giống như các công cụ khác. Nhưng hãy chỉ cho nó một biểu đồ, nó sẽ mô tả biểu đồ đó bằng lời bình thường mà bạn có thể tìm kiếm. Chính khả năng này là điểm độc đáo mà các công cụ khác không sở hữu.
Ví dụ, một biểu đồ giá cả hàng hóa giờ đây trở thành một câu văn: "chỉ số giá hàng hóa theo lĩnh vực, giảm kể từ đỉnh năm 2022". Người dùng tìm kiếm "chỉ số giá hàng hóa kể từ năm 2022" giờ đây có thể tìm thấy trang đó. Trước đây, không có nội dung văn bản nào để khớp.
Hãy tưởng tượng một ảnh chụp vệ tinh của bãi đỗ xe. Nó hoàn toàn không có chữ. OCR không tìm thấy gì, layout tìm thấy một hộp rỗng. Vision LLM sẽ viết: "góc nhìn từ trên cao của một bãi đỗ xe, khoảng một nửa đầy, khoảng bốn mươi chiếc xe". Giờ đây, việc tìm kiếm tỷ lệ lấp đầy bãi đỗ xe đã khả thi. Câu văn đó chính là kết quả phân tích, và chỉ có Vision LLM mới tạo ra được nó.
2. Nó cũng phân tích văn bản và bảng tính như các công cụ khác
Dù khả năng đọc hình ảnh là điểm độc đáo, một trình phân tích chỉ đọc ảnh sẽ vô dụng. Vision LLM cũng đọc văn bản và bảng tính rất tốt, không thua kém các động cơ văn bản trên tài liệu sạch.
Khi áp dụng cho bảng "Framework Core" trong Khung an ninh mạng của NIST, mô hình này đã trả về các cột bảng nguyên vẹn, xử lý tốt cả các ô đã hợp nhất. Đây là cùng một cấu trúc bảng mà Docling và Azure tạo ra từ cùng một trang. Vision LLM không bao giờ tạo ra một đối tượng bảng; nó đọc lưới từ hình ảnh và viết markdown. Do đó, nó thực sự là một trình phân tích, trả về mô hình tái sử dụng giống như các công cụ khác, cộng thêm các hình ảnh mà chúng bỏ lỡ.
3. Chất lượng phụ thuộc vào mô hình: gpt-4o-mini bỏ sót biểu đồ mà gpt-4.1 đọc được
Chất lượng của quá trình phân tích phụ thuộc rất nhiều vào mô hình bạn chọn, và sự khác biệt thể hiện rõ nhất ở các hình ảnh.
 So sánh khả năng đọc biểu đồ giữa gpt-4o-mini và gpt-4.1
So sánh khả năng đọc biểu đồ giữa gpt-4o-mini và gpt-4.1
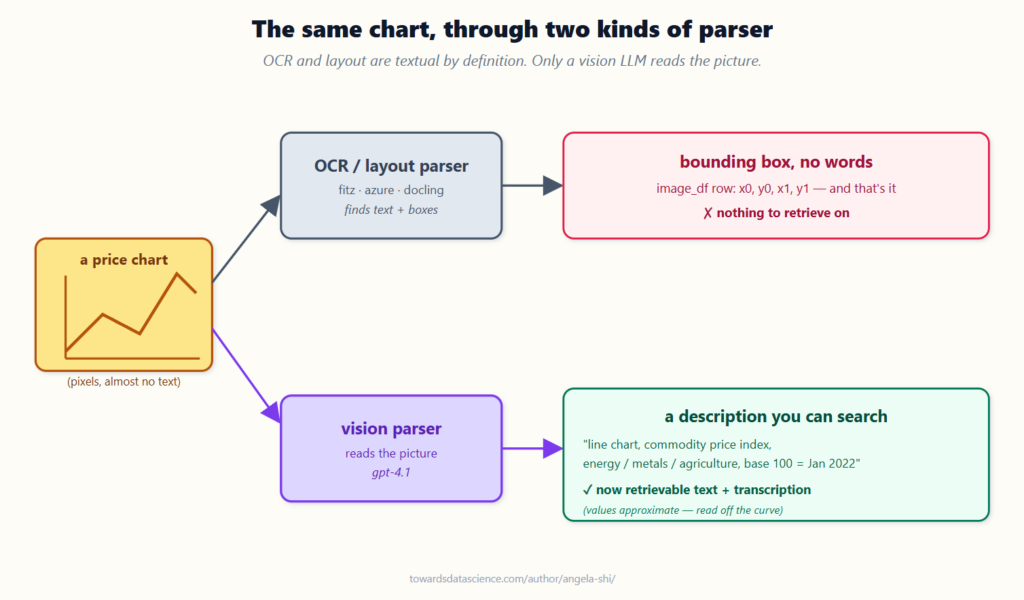
Khi chạy cùng một trang chứa biểu đồ qua cả gpt-4o-mini và gpt-4.1:
- gpt-4o-mini chỉ tìm thấy 3 trong số 6 biểu đồ và gán nhãn sai 2 trong số đó là bảng tính.
- gpt-4.1 tìm thấy tất cả 6 biểu đồ và chuyển ký chính xác các trục dữ liệu xuống từng tháng, bao gồm cả các biểu đồ về "bất ổn chính sách" và "bất thường nhiệt độ" mà mô hình nhỏ hơn đã bỏ sót.
Cả hai đều đọc văn bản và bảng NIST đúng, nhưng mô hình yếu hơn đã thất bại ở hình ảnh — thứ duy nhất bạn mang Vision LLM đến để xử lý. Vì vậy, với trình phân tích này, mô hình là một phần của chất lượng, không chỉ là công cụ điều chỉnh độ trễ và chi phí.
4. Sự đánh đổi trung thực: Độ chính xác và Chi phí
Không có gì là miễn phí, và nhược điểm cần được gọi đúng tên. Không phải vì Vision "không thực sự phân tích", mà vì quá trình phân tích này ít chính xác hơn và tốn kém hơn mỗi trang.
 Sự đánh đổi giữa khả năng và chi phí
Sự đánh đổi giữa khả năng và chi phí
Hai chi phí nổi bật cần lưu ý:
Độ chính xác: Các giá trị mà nó đọc từ một đường cong là xấp xỉ. Hình dạng và nội dung chính là đúng, nhưng một mốc cụ thể có thể bị lệch, vì vậy hãy coi số liệu được chép lại là một manh mối cần kiểm tra, không phải là sự thật tuyệt đối. Tệ hơn, nó có thể âm thầm bỏ sót một phần tử, một hàng trong bảng hoặc một biểu đồ, giống như cách gpt-4o-mini đã bỏ một nửa biểu đồ ở phần trên. Đây là vấn đề về tính đầy đủ, một loại "ảo giác bằng sự bỏ sót" mà trình phân tích xác định (deterministic) như fitz hay Docling không bao giờ mắc phải.
Chi phí: Mỗi trang là một hình ảnh lớn và một lệnh gọi mô hình, được tính phí theo từng trang, không có hộp giới hạn (bounding box) để làm nổi bật sau này. Các trình phân tích văn bản chạy một lần, tốn rất ít chi phí mỗi trang và cung cấp các khoảng văn bản chính xác.
Quy tắc ở đây không phải là "dùng Vision thay thế phân tích", mà là "dùng Vision cho những trang mà các trình phân tích văn bản bị mù".
5. Cách hoạt động: parse_page_vision
Cơ chế khá đơn giản. Hàm này hiển thị trang, gửi hình ảnh đến Vision LLM thông qua lệnh gọi đầu ra có cấu trúc responses.parse, và trả về một đối tượng nhỏ: trang dưới dạng markdown và danh sách các hình ảnh, mỗi hình ảnh có loại, mô tả và bản chép.
page = parse_page_vision("CMO-April-2026.pdf", 10, model="gpt-4.1")
page.markdown # tiêu đề, đoạn văn, bảng
page.figures # một mục cho mỗi biểu đồ / sơ đồ
page.figures[0].description # "biểu đồ đường, chỉ số giá ..."
page.figures[0].transcription # trục, chú giải, giá trị có thể đọc
Hàm này là "anh em" với các trình phân tích fitz, azure_layout và docling. Nó sử dụng hai mô hình Pydantic để thiết lập đầu ra: trang dưới dạng markdown và các mục cho từng hình ảnh. Không có mô hình bố cục hay bước OCR; mô hình đọc trực tiếp các điểm ảnh và điền vào lược đồ.
6. Chế độ nhẹ hơn: Hỏi trực tiếp trang
Có một cách dùng một lần cho cùng khả năng này. Thay vì phân tích trang thành cấu trúc tái sử dụng, hãy đưa cho mô hình trang và một câu hỏi duy nhất, sau đó đọc lại một câu trả lời. Không có markdown, không có chỉ mục, không lưu giữ gì. Điều này hữu ích khi việc xây dựng một mô hình là quá mức cần thiết.
Cả gpt-4o-mini và gpt-4.1 đều trả lời các câu hỏi này theo cách tương tự. Điều quan trọng là hàng thứ ba: khi được hỏi về một thứ không có trên trang, nó từ chối thay vì bịa ra. Con đường null được kích hoạt giúp chế độ này an toàn để sử dụng.
7. Bốn trình phân tích, một cái biết đọc ảnh
Giờ đây chúng ta có bốn động cơ phân tích. Ba cái đọc văn bản và cấu trúc; cái thứ tư đọc những thứ đó và cả cả hình ảnh bên trên.
 Tổng hợp các trình phân tích: fitz, azure, docling và vision
Tổng hợp các trình phân tích: fitz, azure, docling và vision
Trình phân tích Vision nằm ở phía thị giác: hãy sử dụng nó khi một trang chủ yếu là biểu đồ, khi một sơ đồ chứa câu trả lời, khi bản quét quá xuống cấp để OCR đọc được, hoặc khi nội dung hoàn toàn là hình ảnh không có chữ. Nó đắt nhất mỗi trang và ít chính xác nhất về số liệu, nên nó chạy cuối cùng. Nhưng nó là động cơ duy nhất biến một bức tranh thành thứ có thể truy xuất được.
Kết luận
Vision LLM là một trình phân tích: yêu cầu markdown, nó trả về văn bản và bảng tính giống như fitz hay Azure; yêu cầu mô tả hình ảnh, nó trả về thứ duy nhất mà trình phân tích văn bản không thể: những từ có thể tìm kiếm về một hình ảnh. Sự đánh đổi là có thật (ít chính xác hơn, không có bounding box, một lệnh gọi mô hình mỗi trang), vì vậy trình phân tích Vision không thay thế các công cụ văn bản, nó lấp đầy điểm mù của chúng. Chúng đọc những từ trên trang; Vision đọc trang không có từ.
Bài viết liên quan

Phần mềm
Startup Jedify huy động 24 triệu USD để trang bị ngữ cảnh kinh doanh cho tác nhân AI
10 tháng 6, 2026

Phần mềm
Nvidia chính thức khai tử ứng dụng GeForce Control Panel sau 20 năm gắn bó
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026