
Vượt Qua Viết Lệnh (Prompting): Sử Dụng Kỹ Năng (Skills) Trong Khoa Học Dữ Liệu
Bài viết chia sẻ cách tác giả chuyển hóa thói quen trực quan hóa dữ liệu hàng tuần thành một quy trình làm việc tự động hóa bằng AI thông qua "Skills" (Kỹ năng). Đây là các gói hướng dẫn có thể tái sử dụng giúp AI xử lý các tác vụ lặp lại trong khoa học dữ liệu một cách đáng tin cậy và nhất quán hơn. Phương pháp này kết hợp giữa MCP và các kỹ năng tùy chỉnh, giúp tối ưu hóa hiệu suất phân tích và tiết kiệm thời gian đáng kể.

Trong bài viết trước, tôi đã chia sẻ cách sử dụng MCP (Model Context Protocol) để tích hợp các Mô hình Ngôn ngữ Lớn (LLM) vào quy trình khoa học dữ liệu trọn vẹn. Tôi cũng đã đề cập ngắn gọn đến một công cụ hữu ích khác: Skills (Kỹ năng).
Một "Skill" là một gói hướng dẫn có thể tái sử dụng, bao gồm các tệp hỗ trợ tùy chọn. Nó giúp AI xử lý một quy trình làm việc thường xuyên một cách đáng tin cậy và nhất quán hơn. Ở mức tối thiểu, một Skill cần một tệp SKILL.md chứa siêu dữ liệu (tên và mô tả) cũng như hướng dẫn chi tiết về cách hoạt động của kỹ năng đó. Người dùng thường đóng gói nó cùng với các tập lệnh, mẫu và ví dụ để đảm bảo tính chuẩn xác và hiệu quả.
 Ví dụ về các kỹ năng trong Data Science
Ví dụ về các kỹ năng trong Data Science
Tại thời điểm này, bạn có thể tự hỏi tại sao chúng ta lại sử dụng Skills thay vì viết toàn bộ mọi thứ trực tiếp vào ngữ cảnh của Claude Code hay Codex. Một lợi thế lớn là Skills giúp giữ cho ngữ cảnh chính ngắn gọn hơn. Ban đầu, AI chỉ cần tải siêu dữ liệu nhẹ nhàng — nó có thể đọc các hướng dẫn còn lại và tài nguyên đi kèm khi quyết định rằng kỹ năng đó phù hợp. Bạn có thể tìm thấy một bộ sưu tập Skills công cộng tuyệt vời tại skills.sh.
Hãy làm rõ khái niệm này bằng một ví dụ đơn giản.
Ví dụ của tôi — Kỹ Năng Trực Quan Hóa Hàng Tuần
Bối cảnh
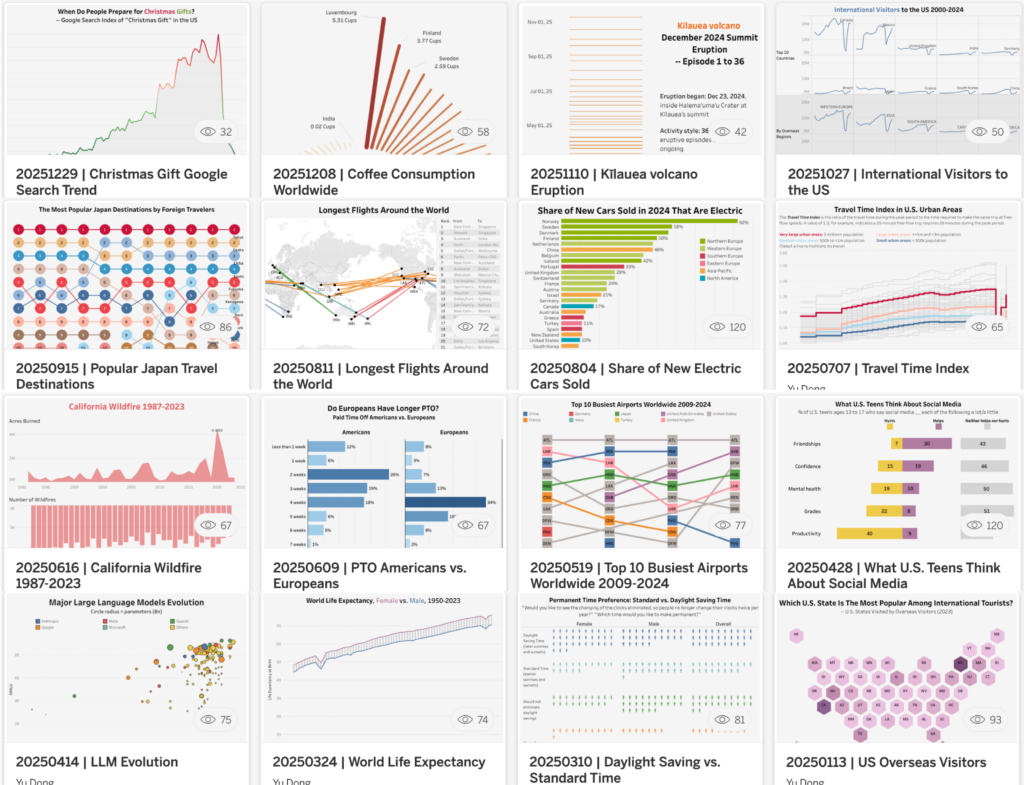
Tôi đã tạo ra một biểu đồ trực quan hóa mỗi tuần kể từ năm 2018 — nếu bạn tò mò, tôi đã viết về hành trình này trong một bài khác. Quá trình này mang tính lặp lại rất cao và thường tiêu tốn của tôi khoảng một giờ mỗi tuần. Do đó, tôi thấy đây là một ứng cử viên xuất sắc để tự động hóa bằng Skills.
Quy trình không có AI
Đây là thói quen hàng tuần của tôi:
- Tìm một bộ dữ liệu thú vị. Các trang web tôi thường ghé để tìm cảm hứng bao gồm Tableau Viz of the Day, Voronoi, The Economics Daily by BLS, r/dataisbeautiful, v.v.
- Mở Tableau, thử nghiệm với dữ liệu, tìm ra các thông tin chi tiết (insights) và xây dựng một biểu đồ kể câu chuyện một cách trực quan.
- Xuất bản nó lên trang web cá nhân.
 Một số biểu đồ trực quan hóa năm 2025
Một số biểu đồ trực quan hóa năm 2025
Quy trình với AI
Mặc dù bước tìm kiếm dữ liệu vẫn thủ công, tôi đã tạo ra hai Skills để tự động hóa bước 2 và 3:
- Một storytelling-viz skill phân tích bộ dữ liệu, xác định các thông tin chi tiết, đề xuất loại biểu đồ và tạo ra một biểu đồ tương tác trực quan, ngắn gọn và tập trung vào việc kể chuyện.
- Một viz-publish skill xuất bản biểu đồ lên trang web của tôi dưới dạng HTML nhúng — tôi sẽ không chia sẻ skill này vì nó rất cụ thể với cấu trúc repo trang web của tôi.
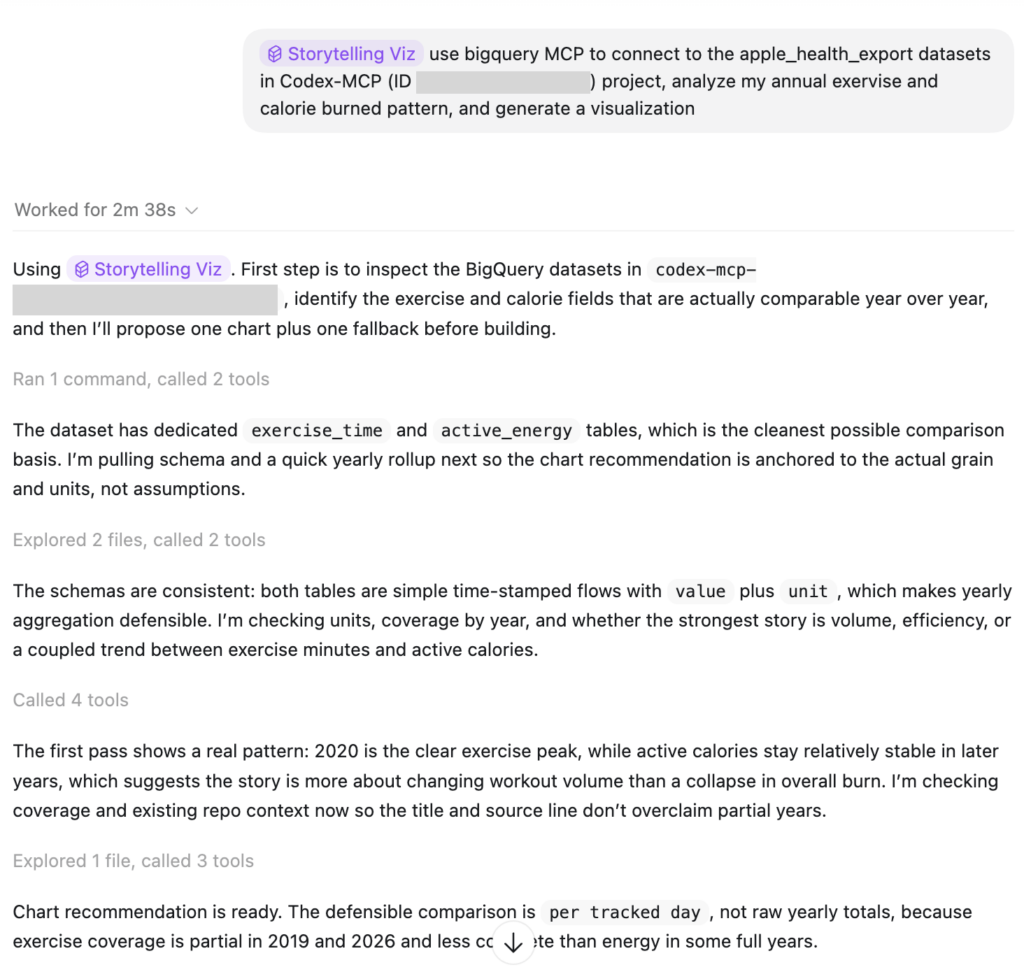
Dưới đây là một ví dụ mà tôi kích hoạt storytelling-viz skill trong Codex Desktop. Tôi đã sử dụng cùng một bộ dữ liệu Apple Health như lần trước, yêu cầu Codex truy vấn dữ liệu từ cơ sở dữ liệu Google BigQuery, sau đó sử dụng skill để tạo biểu đồ. Nó đã có thể làm nổi bật một thông tin chi tiết về thời gian tập thể dục hàng năm so với calo đốt cháy, và đề xuất loại biểu đồ cùng với lý do và sự đánh đổi.
Toàn bộ quá trình này mất ít hơn 10 phút, và dưới đây là kết quả — nó bắt đầu bằng một tiêu đề dẫn dắt dựa trên thông tin chi tiết, tiếp theo là một biểu đồ tương tác sạch sẽ, các cảnh báo và nguồn dữ liệu. Tôi đã kiểm tra skill này với vài biểu đồ hàng tuần gần đây và bạn có thể tìm thấy thêm các ví dụ trực quan hóa trong repo của skill.
 Quy trình xây dựng skill
Quy trình xây dựng skill
Tôi Đã Xây Dựng Nó Như Thế Nào
Bây giờ chúng ta đã xem qua kết quả, hãy để tôi hướng dẫn bạn cách tôi xây dựng skill này.
Bước 1: Bắt đầu với một kế hoạch
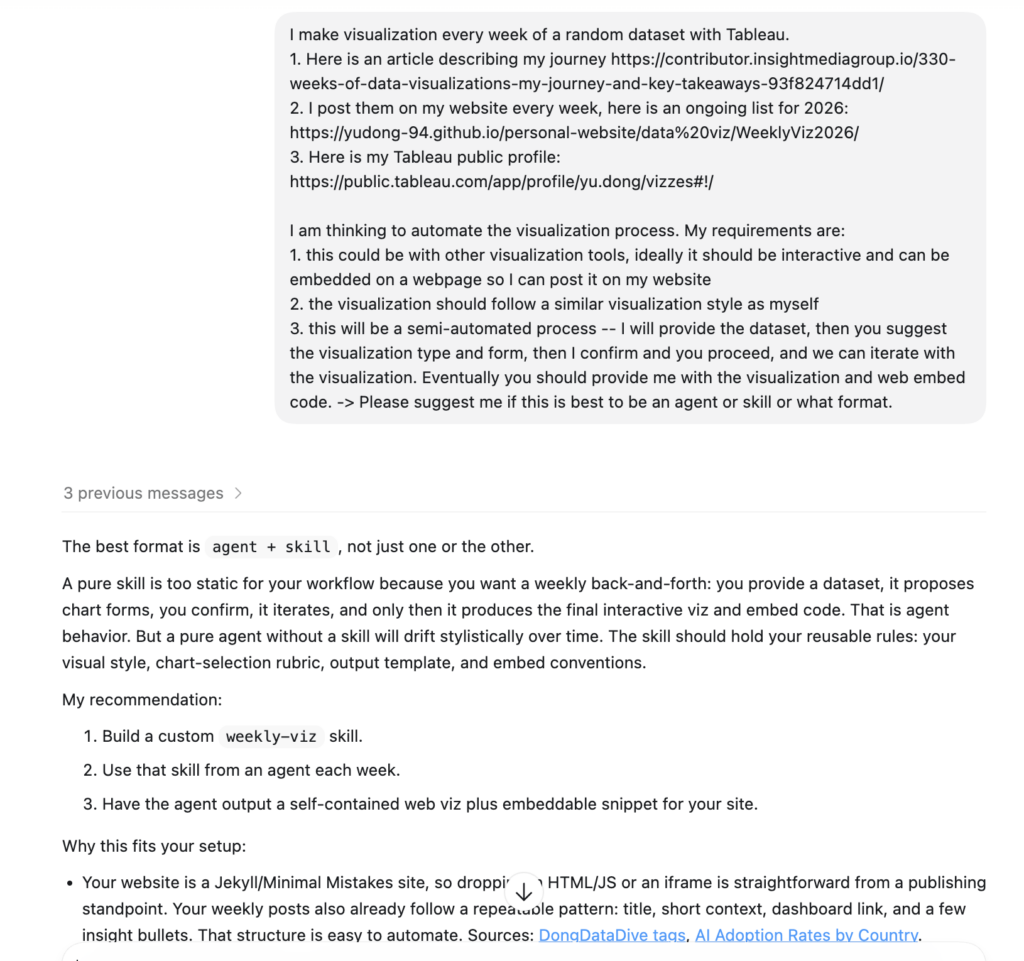
Như tôi đã chia sẻ trong bài viết trước, tôi thích chốt kế hoạch với AI trước trước khi bắt tay vào thực hiện. Ở đây, tôi bắt đầu bằng cách mô tả quy trình trực quan hóa hàng tuần của mình và mục tiêu tự động hóa nó. Chúng tôi đã thảo luận về công nghệ, các yêu cầu và định nghĩa về một kết quả đầu ra "tốt". Điều này dẫn đến phiên bản đầu tiên của skill.
Điều thú vị là bạn không cần tạo tệp SKILL.md thủ công — chỉ cần yêu cầu Claude Code hoặc Codex tạo một skill cho trường hợp sử dụng của bạn, và nó có thể tạo phiên bản ban đầu cho bạn (nó sẽ kích hoạt một skill để tạo ra một skill khác).
Bước 2: Kiểm tra và lặp lại
Tuy nhiên, phiên bản đầu tiên đó chỉ giúp tôi đạt được 10% quy trình trực quan hóa lý tưởng — nó có thể tạo biểu đồ, nhưng các loại biểu đồ thường không tối ưu, phong cách thị giác không nhất quán và thông điệp chính không luôn được làm nổi bật, v.v.
90% còn lại yêu cầu các cải tiến lặp đi lặp lại. Dưới đây là một số chiến lược đã giúp ích.
1. Chia sẻ kiến thức của riêng tôi Trong suốt tám năm qua, tôi đã thiết lập các phương pháp tốt nhất và sở thích trực quan hóa riêng. Tôi muốn AI tuân theo các mẫu này thay vì phát minh ra một phong cách mới mỗi lần. Do đó, tôi đã chia sẻ các ảnh chụp màn hình trực quan hóa của mình cùng với hướng dẫn phong cách. AI đã có thể tóm tắt các nguyên tắc chung và cập nhật hướng dẫn của skill tương ứng.
2. Nghiên cứu tài nguyên bên ngoài Có rất nhiều tài nguyên trực tuyến về thiết kế trực quan hóa dữ liệu tốt. Một bước hữu ích khác mà tôi thực hiện là yêu cầu AI nghiên cứu các chiến lược trực quan hóa tốt hơn từ các nguồn nổi tiếng và các skill công khai tương tự. Điều này đã thêm các góc nhìn mà tôi chưa tài liệu hóa rõ ràng, làm cho skill có tính mở rộng và mạnh mẽ hơn.
3. Học từ thử nghiệm Kiểm tra là rất cần thiết để xác định các lĩnh vực cần cải thiện. Tôi đã kiểm tra skill này với hơn 15 bộ dữ liệu khác nhau để quan sát cách nó hoạt động và cách kết quả đầu ra so sánh với các biểu đồ của riêng tôi. Quá trình đó đã giúp tôi đề xuất các cập nhật cụ thể, chẳng hạn như:
- Chuẩn hóa lựa chọn phông chữ và bố cục.
- Kiểm tra xem trước trên máy tính để bàn và di động để tránh chồng lấn nhãn và chú thích.
- Làm cho biểu đồ dễ hiểu ngay cả khi không có tooltip.
- Luôn yêu cầu nguồn dữ liệu và liên kết nó trong biểu đồ.
Bạn có thể tìm thấy phiên bản mới nhất của storytelling-viz skill tại đây. Hãy thoải mái thử nghiệm và cho tôi biết bạn nghĩ sao nhé.
Bài Học Cho Các Nhà Khoa Học Dữ Liệu
Khi nào Skills hữu ích
Dự án trực quan hóa hàng tuần của tôi chỉ là một ví dụ, nhưng Skills có thể hữu ích trong nhiều quy trình khoa học dữ liệu lặp lại. Chúng đặc biệt có giá trị khi bạn có một nhiệm vụ xảy ra thường xuyên, tuân theo một quy trình bán cấu trúc, phụ thuộc vào kiến thức miền và khó xử lý chỉ với một lời nhắc (prompt) đơn lẻ.
Ví dụ: điều tra sự biến động của chỉ số X. Bạn có thể đã biết các nguyên nhân phổ biến của X, vì vậy bạn luôn bắt đầu bằng cách phân tích theo phân khúc A/B/C và kiểm tra các chỉ số phễu D và E. Đây chính xác là quá trình bạn có thể đóng gói vào một skill, để AI tuân theo cùng một kịch bản phân tích và xác định nguyên nhân gốc rễ cho bạn.
Ví dụ khác: giả sử bạn планируете chạy một thí nghiệm ở vùng A, và bạn muốn kiểm tra các thí nghiệm khác đang chạy trong cùng khu vực. Trước đây, bạn sẽ tìm kiếm từ khóa trên Slack, đào sâu qua Google Docs và mở nền tảng thí nghiệm nội bộ để xem xét các thí nghiệm được gắn thẻ vùng đó. Bây giờ, bạn có thể tóm tắt các bước chung này vào một skill và yêu cầu LLM thực hiện nghiên cứu toàn diện và tạo báo cáo về các thí nghiệm liên quan cùng với mục tiêu, thời lượng, lưu lượng, trạng thái và tài liệu của chúng.
Nếu quy trình của bạn bao gồm nhiều thành phần độc lập và có thể tái sử dụng, bạn nên chia chúng thành các skill riêng biệt. Trong trường hợp của tôi, tôi đã tạo hai skill — một để tạo biểu đồ và một để xuất bản nó lên blog. Điều này làm cho các phần mô-đun hơn và dễ dàng tái sử dụng trong các quy trình khác sau này.
Skills và MCP hoạt động rất tốt cùng nhau. Tôi đã sử dụng BigQuery MCP và skill trực quan hóa trong một lệnh, và nó đã tạo thành công một biểu đồ dựa trên dữ liệu của tôi trong BigQuery. MCP giúp mô hình truy cập các công cụ bên ngoài một cách mượt mà, và skill giúp nó tuân theo quy trình đúng đắn cho một nhiệm vụ nhất định. Do đó, sự kết hợp này rất mạnh mẽ và bổ sung cho nhau.
Lưu ý cuối cùng về dự án trực quan hóa hàng tuần của tôi
Bây giờ mà tôi có thể tự động hóa 80% quá trình trực quan hóa hàng tuần của mình, tại sao tôi vẫn tiếp tục làm việc này?
Khi tôi bắt đầu thói quen này vào năm 2018, mục tiêu là luyện tập Tableau, công cụ BI chính được sử dụng bởi công ty của tôi. Tuy nhiên, mục đích đã thay đổi theo thời gian — bây giờ tôi sử dụng nghi thức hàng tuần này để khám phá các bộ dữ liệu khác nhau mà tôi sẽ không bao giờ gặp phải trong công việc, mài giũa trực giác dữ liệu và khả năng kể chuyện, và nhìn thế giới qua lăng kính của dữ liệu. Vì vậy, đối với tôi, thực sự không phải là về công cụ, mà là quá trình khám phá. Và đó là lý do tôi dự định tiếp tục làm điều đó, ngay cả trong kỷ nguyên AI.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng hoạt động hàng tháng
16 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026