
Xây dựng Hệ thống Observability Production trên Kubernetes AWS với OpenTelemetry Operator
Môi trường Kubernetes hiện đại mang lại tính linh hoạt nhưng cũng đặt ra thách thức lớn về khả năng quan sát (observability) ở quy mô. Bài viết này sẽ khám phá cách xây dựng hệ thống giám sát production-grade trên AWS bằng Kubernetes và OpenTelemetry Operator, bao gồm kiến trúc, triển khai và các phương pháp tối ưu hóa hiệu quả.

Môi trường Kubernetes hiện đại mang tính động, phân tán và vô cùng phức tạp. Mặc dù điều này cho phép khả năng mở rộng và linh hoạt cao, nó cũng giới thiệu một thách thức mang tính sống còn: Khả năng quan sát ở quy mô lớn (Observability at scale).
Trong các hệ thống production, việc chỉ đơn thuần thu thập logs hay metrics là chưa đủ. Bạn cần một chiến lược observability thống nhất cung cấp đầy đủ ba yếu tố:
- Metrics (chỉ số sức khỏe hệ thống)
- Logs (nhật ký sự kiện & debugging)
- Traces (dòng chảy yêu cầu giữa các dịch vụ)
Trong bài viết này, chúng ta sẽ khám phá cách xây dựng một hệ thống observability chuẩn production trên AWS sử dụng Kubernetes và OpenTelemetry Operator, bao gồm kiến trúc, triển khai thực tế và các best practices.
Tại sao Observability lại quan trọng trong Kubernetes
Kubernetes giới thiệu nhiều lớp trừu tượng khác nhau, khiến việc giám sát truyền thống trở nên khó khăn:
- Pods có tính tạm thời (ephemeral)
- Services tự động scale theo nhu cầu
- Đường dẫn mạng phi tuyến tính
- Các lỗi thường phân tán rải rác
Nếu không có observability phù hợp, bạn sẽ gặp khó khăn trong việc:
- Xác định các nút thắt cổ chai (bottlenecks)
- Debug các vấn đề về độ trễ (latency)
- Truy vết lỗi qua các dịch vụ khác nhau
- Giám sát sức khỏe tổng thể của hệ thống
Tổng quan Kiến trúc Observability
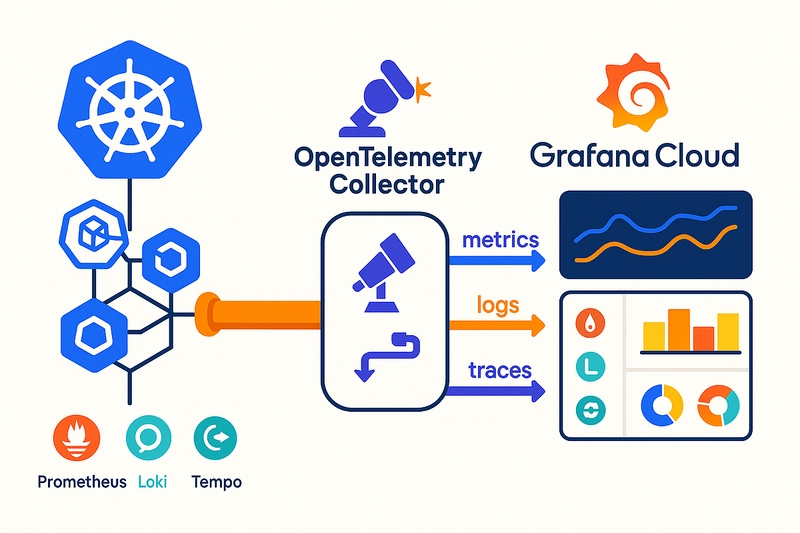 Kiến trúc Observability trên Kubernetes sử dụng OpenTelemetry Operator và Grafana Stack
Kiến trúc Observability trên Kubernetes sử dụng OpenTelemetry Operator và Grafana Stack
Kiến trúc observability end-to-end trong Kubernetes sử dụng OpenTelemetry Operator, Collector và stack Grafana.
Luồng hoạt động của Kiến trúc
- Các ứng dụng được instrumentation sử dụng OpenTelemetry.
- OpenTelemetry Operator tự động inject các tác nhân instrumentation (auto-instrumentation).
- Dữ liệu telemetry (thông tin giám sát) được thu thập bởi OpenTelemetry Collector.
- Dữ liệu được xuất ra các backend:
- Prometheus (cho metrics)
- Loki (cho logs)
- Tempo (cho traces)
- Grafana trực quan hóa tất cả các tín hiệu này.
Các thành phần chính của Stack
OpenTelemetry Operator
- Tự động inject các tác nhân vào pods.
- Quản lý collectors dưới dạng Custom Resource Definitions (CRDs).
- Chuẩn hóa các pipeline telemetry.
OpenTelemetry Collector
- Tiếp nhận dữ liệu telemetry.
- Xử lý và làm sạch dữ liệu.
- Xuất dữ liệu sang các backend lưu trữ.
Prometheus (Metrics)
- Theo dõi CPU / Bộ nhớ.
- Tỷ lệ yêu cầu (Request rate).
- Tỷ lệ lỗi (Error rate).
- Độ trễ (Latency).
Grafana Tempo (Traces)
- Distributed tracing (truy vết phân tán).
- Phụ thuộc giữa các dịch vụ.
- Phân tích độ trễ chi tiết.
Loki (Logs)
- Tổng hợp nhật ký (log aggregation).
- Tương quan với traces để dễ dàng debug.
Grafana
- Dashboard trực quan.
- Xem logs và traces tại một nơi.
Triển khai trên AWS (Kiến trúc dựa trên EKS)
Khi triển khai trên AWS, kiến trúc thường bao gồm:
- Amazon EKS → chạy các workloads ứng dụng.
- OpenTelemetry Operator → xử lý instrumentation.
- OpenTelemetry Collector -> quản lý pipeline dữ liệu.
- Amazon S3 → lưu trữ dữ liệu lâu dài.
- Grafana → trực quan hóa và giám sát.
Ví dụ về Auto-Instrumentation
Dưới đây là cấu hình YAML để tự động instrumentation cho một ứng dụng Java:
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: java-instrumentation
spec:
java:
image: ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-java
Cấu hình OpenTelemetry Collector
Cấu hình Collector để thu thập dữ liệu và xuất ra Prometheus và Tempo:
apiVersion: opentelemetry.io/v1alpha1
kind: OpenTelemetryCollector
metadata:
name: otel-collector
spec:
config: |
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
exporters:
prometheus:
endpoint: "0.0.0.0:8889"
tempo:
endpoint: tempo:4317
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [tempo]
Quy trình tương quan dữ liệu (Correlation Workflow)
Khi có sự cố xảy ra, quy trình xử lý tiêu chuẩn là:
- Cảnh báo (Alert) được kích hoạt.
- Kiểm tra Metrics để xem cái gì đang sai.
- Kiểm tra Traces để tìm ra vị trí lỗi.
- Kiểm tra Logs để hiểu tại sao lỗi đó xảy ra.
- Xác định nguyên nhân gốc rễ (Root cause).
Best Practices cho Môi trường Production
- Sử dụng Sampling (lấy mẫu) để giảm tải dữ liệu.
- Scale các Collectors để xử lý lượng dữ liệu lớn.
- Tách biệt các pipeline cho các loại dữ liệu khác nhau.
- Giám sát chính các Collector để đảm bảo chúng hoạt động ổn định.
- Bảo mật các dòng telemetry dữ liệu.
Những cạm bẫy thường gặp
- Không sử dụng Collector và để application export trực tiếp.
- Thu thập quá nhiều dữ liệu (Over-collection).
- Không áp dụng Sampling, gây nghẽn hệ thống.
- Thiếu sự tương quan giữa Metrics, Logs và Traces.
Kịch bản Debug thực tế trong Production
Hãy xem xét một ví dụ thực tế để hiểu cách observability hỗ trợ giải quyết sự cố.
Bối cảnh
Người dùng báo cáo rằng checkout service đang chậm trong một ứng dụng thương mại điện tử chạy trên môi trường production.
Bước 1: Phát hiện vấn đề (Metrics)
Dashboard trên Grafana cho thấy:
- Độ trễ tăng vọt ở checkout service.
- Spike (đỉnh) trong thời gian phản hồi (P95/P99).
Điều này chỉ ra một vấn đề về hiệu suất nhưng chưa tiết lộ nguyên nhân gốc rễ.
Bước 2: Truy vết yêu cầu (Traces)
Sử dụng Grafana Tempo:
- Xác định các trace (vết) chậm.
- Phân tích luồng yêu cầu.
Ví dụ trace: Frontend → Cart Service → Checkout Service → Payment Service
Quan sát: Checkout service đang mất thời gian bất thường.
Bước 3: Phân tích chi tiết (Drill Down into Spans)
Bên trong trace:
- Một span cụ thể cho thấy độ trễ cao.
- Câu lệnh truy vấn database bên trong checkout service đang rất chậm.
Bước 4: Kiểm tra Nhật ký (Logs)
Sử dụng Loki:
- Lọc logs cho checkout service.
- Tìm các lỗi hoặc cảnh báo.
Tìm thấy:
- Lỗi timeout database.
- Logs về các câu truy vấn chậm.
Bước 5: Xác định Nguyên nhân gốc rễ
- Câu truy vấn database không hiệu quả.
- Thiếu index (chỉ mục) trong bảng dữ liệu.
Bước 6: Giải quyết vấn đề
- Tối ưu hóa câu truy vấn.
- Thêm index vào database.
- Giảm độ trễ phản hồi.
Kết quả
- Độ trễ được giảm đáng kể.
- Hệ thống ổn định trở lại.
- Thời gian giải quyết sự cố (incident resolution) nhanh hơn nhiều.
Thông tin chính yếu
Quy trình này minh họa sức mạnh của việc tương quan metrics, traces và logs:
- Metrics → Phát hiện (Detect)
- Traces → Định vị (Locate)
- Logs → Giải thích (Explain)
Điều này giúp giảm đáng kể MTTR (Mean Time to Resolution) trong các hệ thống production.
Lời kết
Sự kết hợp giữa:
- OpenTelemetry Operator
- OpenTelemetry Collector
- Prometheus, Loki, Tempo
- Grafana
sẽ tạo nên một nền tảng observability có khả năng mở rộng, chuẩn production trên AWS.
Hãy nhớ rằng, Observability không phải là một lựa chọn tùy chọn, nó là nền tảng cốt lõi để vận hành hệ thống hiện đại thành công.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026

Công nghệ
Pinterest áp dụng "vân tay nội dung" để loại bỏ URL trùng lặp trên hàng triệu tên miền
08 tháng 6, 2026