
Xây dựng Hệ thống RAG Doanh nghiệp Tối giản: Từ PDF đến Câu trả lời Có Dẫn Chứng
Bài viết này giới thiệu cách xây dựng một pipeline RAG (Retrieval-Augmented Generation) cơ bản nhưng hiệu quả, sử dụng Python để xử lý tài liệu PDF thực tế. Hệ thống không chỉ đưa ra câu trả lời chính xác mà còn cung cấp dẫn chứng rõ ràng và tự động đánh dấu nguồn trên tài liệu gốc.

Cách nhanh nhất để hiểu RAG (Retrieval-Augmented Generation) là gì chính là tự tay xây dựng phiên bản nhỏ nhất có thể hoạt động được, chạy nó trên một tài liệu thực và quan sát kỹ những gì vừa xảy ra.
Đó chính là mục đích của bài viết này. Chỉ với khoảng một trăm dòng Python (không cần cơ sở dữ liệu vector, không cần framework phức tạp, không cần agents), chúng ta sẽ vận hành hệ thống trên bài báo nghiên cứu nổi tiếng "Attention Is All You Need". Kết quả trả về sẽ là một câu trả lời có dẫn nguồn cụ thể, với các dòng gốc được đánh dấu nổi bật trên trang tài liệu.
 Pipeline RAG cơ bản
Pipeline RAG cơ bản
Bốn thành phần cốt lõi của Pipeline
Pipeline tối giản này bao gồm bốn "gạch" (bricks) chính cộng với một bước hiển thị tùy chọn. Mỗi thành phần có đầu vào và đầu ra rõ ràng; dữ liệu truyền từ bước này sang bước khác chính là những gì chúng ta lưu lại.
- Phân tích tài liệu (Document Parsing): Chuyển đổi đường dẫn PDF thành
line_df(một dòng dữ liệu cho mỗi dòng văn bản, bao gồm số trang, số dòng, nội dung và tọa độ khung giới hạn - bounding box). - Phân tích câu hỏi (Question Parsing): Biến đổi câu hỏi của người dùng thành
ParsedQuestion, bao gồm câu hỏi đã được chuẩn hóa và danh sách các từ khóa kiểm tra. - Truy xuất (Retrieval): Tiêu thụ
ParsedQuestionvà trả về số trang top-k (và số dòng khớp trong các trang đó). - Tạo câu trả lời (Generation): Kết hợp câu hỏi,
line_dfvà số trang đã truy xuất để tạo raAnswerWithEvidence— một đối tượng JSON có cấu trúc chứa câu trả lời, đoạn dẫn chứng, độ tin cậy, lý do và các trích dẫn chính xác.
Bước cuối cùng là Chú thích PDF (PDF Annotation), dùng để vẽ hình chữ nhật quanh các dòng được trích dẫn ngay trên tài liệu gốc.
Tại sao cần Retrieval khi LLM có thể đọc hết?
Có thể bạn sẽ hỏi: "Với một bài báo 15 trang, LLM hoàn toàn có thể đọc hết. Tại sao phải phức tạp thêm bước truy xuất?"
Đây là một câu hỏi hợp lý cho một tài liệu ngắn. Tuy nhiên, trong môi trường doanh nghiệp thực tế, câu hỏi thường mang tính tổng hợp, so sánh hoặc tóm tắt từ nhiều đoạn văn khác nhau, không chỉ là tìm một câu đơn lẻ.
Hơn nữa, tài liệu doanh nghiệp thường rất dài: hợp đồng bảo hiểm 300 trang, hồ sơ quy định 500 trang, hay các thông số kỹ thuật đa tập. Việc gửi toàn bộ nội dung cho LLM tốn kém chi phí và làm loãng sự chú ý của mô hình vào các trang không liên quan. Khi cần tìm kiếm thông tin trên hàng ngàn tài liệu cùng lúc, chiến lược "ném tất cả vào" sẽ thất bại. Retrieval chính là chìa khóa để hệ thống tồn tại khi mở rộng quy mô.
Chi tiết các thành phần
1. Phân tích tài liệu (Document Parsing)
Chúng ta sử dụng thư viện pymupdf để trích xuất từng dòng văn bản cùng vị trí của nó trên trang. Đầu ra là một DataFrame nơi mỗi dòng là một dòng văn bản, kèm theo tọa độ x0, y0, x1, y1. Các tọa độ này rất quan trọng vì chúng là cơ sở để chúng ta vẽ các khung đánh dấu (highlight) trên PDF gốc ở bước cuối cùng.
2. Phân tích câu hỏi (Question Parsing)
Trước khi đưa câu hỏi đi truy xuất, chúng ta chạy nó qua một lệnh gọi LLM nhỏ. Mục tiêu là trích xuất các từ khóa hữu ích nhất để tìm kiếm tài liệu: các cụm từ ngắn mà tài liệu có khả năng sử dụng, không nhất thiết là từ字 đúng của câu hỏi.
Bước này không thực hiện logic truy xuất hay tính toán embedding. Nó giúp giải thích lý do tại sao hệ thống chọn một trang cụ thể, giúp việc gỡ lỗi (debug) dễ dàng hơn nhiều so với một "hộp đen".
3. Truy xuất (Retrieval): Minh bạch hơn là Opaque
Nhiều hướng dẫn RAG tiêu chuẩn sử dụng embeddings và độ tương đồng cosine (cosine similarity). Tuy nhiên, phiên bản tối giản này cố tình không dùng embeddings vì một lý do: tính minh bạch.
Cosine similarity trả về một con số như 0.7798 và yêu cầu người dùng tin rằng "trang 6 liên quan đến câu hỏi". Nhưng không ai thực sự hiểu ý nghĩa của con số 0.78 hay tại sao nó cao hơn 0.65. Trong môi trường doanh nghiệp, người dùng thường đặt câu hỏi nhiều nhất về bước truy xuất: "Tại sao hệ thống nhìn trang này mà không phải trang kia?"
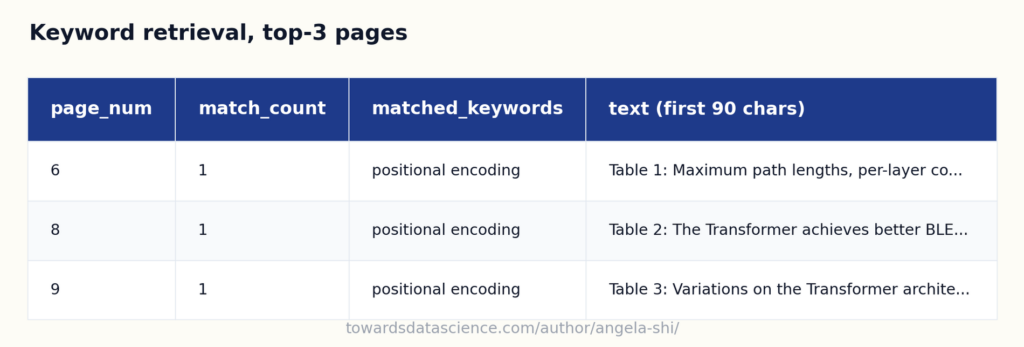
Do đó, phiên bản tối giản sử dụng khớp từ khóa (keyword matching). Chúng ta đếm xem có bao nhiêu từ khóa từ câu hỏi xuất hiện trên mỗi trang và giữ lại top 3 trang có nhiều từ khóa nhất. Bất kỳ ai cũng có thể đọc bảng kết quả và thấy tại sao một trang được chọn.
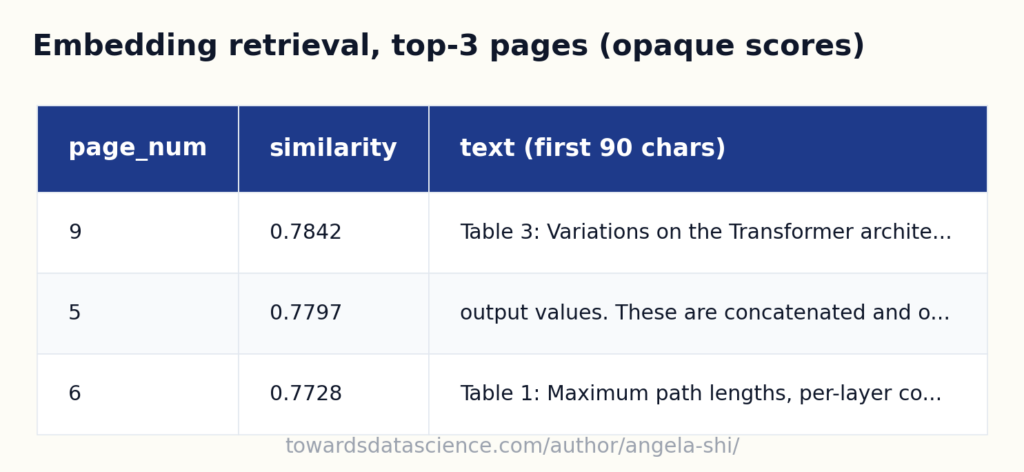 Bảng kết quả khớp từ khóa
Bảng kết quả khớp từ khóa
Mặc dù embeddings có lợi thế về việc xử lý từ đồng nghĩa, nhưng keyword matching mang lại khả năng kiểm chứng trực quan. Đây là nền tảng quan trọng trước khi thêm các lớp phức tạp hơn.
4. Tạo câu trả lời (Generation)
Chúng ta gửi các dòng đã truy xuất cho LLM cùng với câu hỏi, được định dạng dưới dạng khối tab-separated để LLM nhìn thấy tọa độ chính xác cần dẫn chứng.
Sử dụng pydantic, chúng ta định nghĩa một lược đồ AnswerWithEvidence buộc mô hình phải điền vào các trường: start_page_num, start_line_num, end_page_num, end_line_num, confidence, justification, quotes, v.v.
Điều này đảm bảo câu trả lời được "neo" (grounded) vào thực tế. Mô hình không thể bị ảo giác (hallucinate) về một dẫn chứng vì nó chỉ nhìn thấy các dòng từ các trang đã truy xuất, và lược đồ buộc nó phải cung cấp một phạm vi (trang, dòng) thực tế mà chúng ta có thể kiểm tra.
5. Chú thích PDF (PDF Annotation)
Đây là phần thú vị nhất. Sử dụng đoạn dẫn chứng từ câu trả lời, chúng ta vẽ các hình chữ nhật trực tiếp lên PDF nguồn.
 Kết quả PDF được đánh dấu
Kết quả PDF được đánh dấu
Quá trình này bao gồm ba bước đơn giản: mở rộng đoạn dẫn chứng, gộp các khung giới hạn theo trang, và vẽ các hình chữ nhật. Kết quả là một file PDF có thể mở và kiểm tra trực quan, đóng lại vòng tuần hoàn giữa nhận định của LLM và tài liệu gốc.
Kết luận
Hệ thống RAG tối giản này là xương sống của mọi thứ phức tạp hơn sau này. Nó chứng minh rằng với ít phụ thuộc (chỉ cần pymupdf, openai, pandas, pydantic), chúng ta có thể xây dựng một hệ thống thông minh tài liệu doanh nghiệp hoạt động thực tế.
Mỗi khối xây dựng này đều ẩn chứa những giả định đáng để suy ngẫm và cải tiến trong tương lai: từ việc phân tích bảng biểu phức tạp, xử lý câu hỏi phức hợp, đến việc kết hợp keyword matching với embeddings để có được lợi ích của cả hai phương pháp. Nhưng quan trọng nhất, hệ thống này dạy chúng ta một phản xạ đúng đắn: bộ truy xuất phải có thể kiểm toán được (auditable).


