
Xây dựng hệ thống xử lý tài liệu với S3, Textract, Step Functions và EventBridge
Bài viết giới thiệu cách xây dựng một pipeline xử lý tài liệu toàn diện trên AWS, sử dụng S3 để lưu trữ, Textract cho OCR, Step Functions điều phối với Distributed Map mở rộng quy mô, và EventBridge để tích hợp hệ thống. Quy trình bao gồm xử lý bất đồng bộ, đánh giá thủ công và tối ưu chi phí, phù hợp cho các ứng dụng thực tế tại Việt Nam.

Xây dựng hệ thống xử lý tài liệu với S3, Textract, Step Functions và EventBridge
Bài viết này trình bày một kiến trúc pipeline xử lý tài liệu chuyên sâu trên AWS, tích hợp nhiều dịch vụ để tạo ra một quá trình tự động hóa, dễ mở rộng và có khả năng đánh giá thủ công. Hệ thống sử dụng:
- Amazon S3 làm nơi tiếp nhận và lưu trữ tài liệu cùng kết quả.
- Amazon Textract đảm nhiệm OCR và trích xuất cấu trúc dữ liệu.
- AWS Step Functions điều phối luồng công việc, dùng cả Distributed Map để mở rộng xử lý theo batch.
- Amazon EventBridge quản lý luồng sự kiện, giúp hệ thống downstream có thể độc lập đăng ký sự kiện.
Kiến trúc phù hợp với các doanh nghiệp cần xử lý tài liệu đa trang, khối lượng lớn và đảm bảo việc kiểm soát, audit, đồng thời tích hợp được bước đánh giá con người khi cần thiết.
Tại sao mẫu kiến trúc này hiệu quả?
Trong thực tế, xử lý tài liệu không chỉ đơn giản là chạy OCR và lưu json. Các đặc điểm cần giải quyết gồm:
- Xử lý các file PDF nhiều trang theo cách bất đồng bộ.
- Tải tài liệu với tải trọng đột biến (ví dụ cuối ngày có hàng loạt file đổ về).
- Truy xuất lịch sử đầy đủ cho kiểm định, tuân thủ pháp luật.
- Bước đánh giá thủ công khi hệ thống không chắc chắn hoặc dữ liệu thiếu/nhầm.
- Dễ dàng tích hợp với các hệ thống phía sau.
Kiến trúc này xử lý tốt những yêu cầu đó và dễ dàng mở rộng từ demo lên môi trường sản xuất.
Mô tả pipeline xây dựng
Pipeline gồm 2 chế độ xử lý:
-
Xử lý tài liệu đơn lẻ theo sự kiện
- File được tải lên S3 bucket đầu vào.
- EventBridge bắt sự kiện này và kích hoạt luồng Step Functions xử lý toàn diện cho tài liệu đó.
-
Xử lý theo batch
- Chuẩn bị manifest (file JSON/CSV hoặc danh sách keys các tài liệu).
- Step Functions dùng Distributed Map để sinh riêng các luồng con cho từng tài liệu.
- Mỗi luồng con xử lý tài liệu độc lập, giữ nguyên logic.
Cách tổ chức này giúp giữ cho logic xử lý nhất quán trong mọi trường hợp, đồng thời dễ mở rộng.
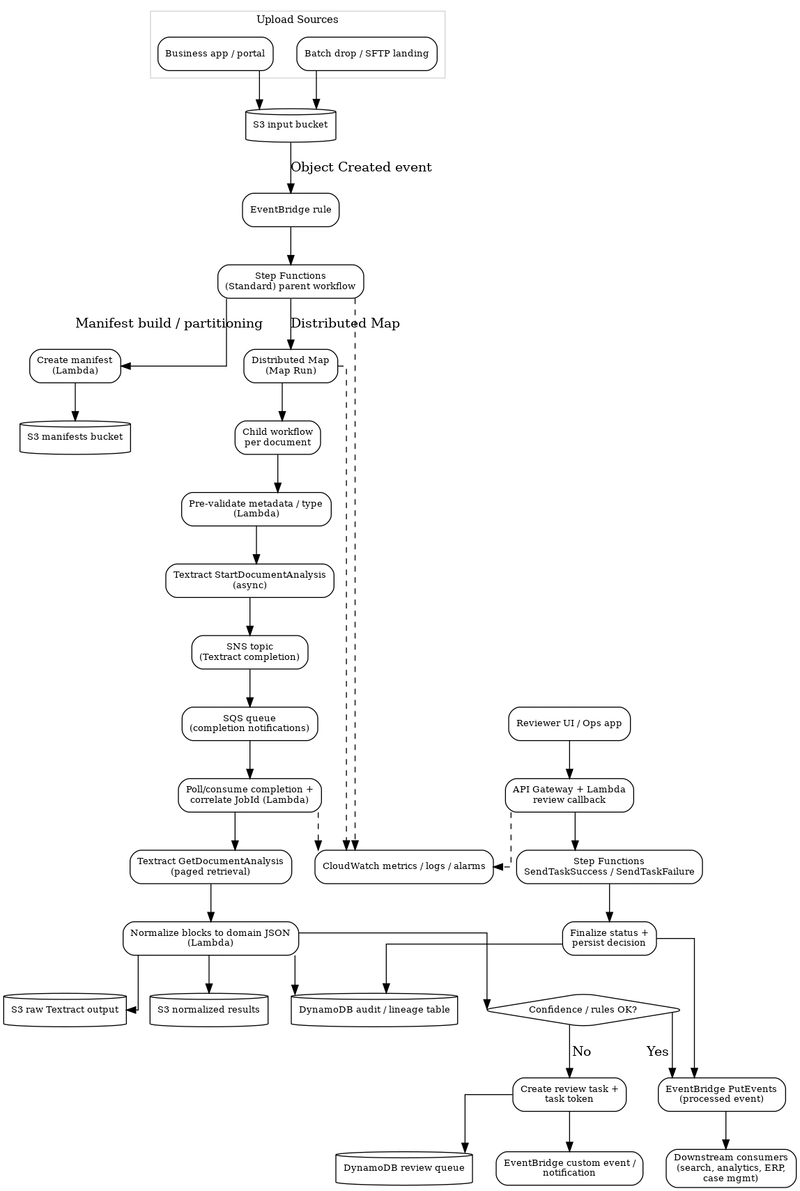 Kiến trúc tổng quan pipeline xử lý tài liệu trên AWS
Kiến trúc tổng quan pipeline xử lý tài liệu trên AWS
Tổng quan kiến trúc hoạt động
- Tài liệu được upload vào bucket S3 đầu vào.
- S3 phát sự kiện lên EventBridge.
- EventBridge kích hoạt luồng cha (parent workflow) trên Step Functions.
- Luồng cha chuẩn bị manifest xử lý (đơn hoặc danh sách batch).
- Distributed Map khởi chạy luồng con (child workflow) cho từng tài liệu.
- Mỗi luồng con:
- Xác thực đầu vào.
- Khởi chạy Textract bất đồng bộ.
- Kiểm tra trạng thái tài liệu cho đến khi hoàn thành.
- Lấy kết quả, chuẩn hóa và enrich dữ liệu.
- Lưu trữ kết quả thô và kết quả đã chuẩn hóa.
- Ghi lại bản ghi audit.
- Với trường hợp dữ liệu không chắc chắn, chuyển sang bước đánh giá thủ công.
- Thông báo sự kiện hoàn thành qua EventBridge.
- Các hệ thống downstream tiêu thụ sự kiện đã xử lý.
Chi tiết từng bước chính
1) Tiếp nhận tài liệu với S3 và EventBridge
-
Tài liệu upload theo cấu trúc khóa mang tính tổ chức như
s3://my-docs-incoming/raw/YYYY/MM/DD/<tenant>/<document>.pdf
giúp quản lý vòng đời, phân vùng người dùng, debug, tính chi phí và replay dễ dàng. -
S3 thiết lập gửi sự kiện
Object Createdđến EventBridge với rule lọc các tài liệu trongraw/.
2) Luồng cha điều phối trên Step Functions
-
Sử dụng kiểu Standard workflow để ưu tiên khả năng chờ lâu, retry, tạm dừng đợi đánh giá thủ công.
-
Luồng cha thực hiện:
- Phân tích event đầu vào (đơn hay batch).
- Tạo manifest xử lý.
- Giới hạn concurrency để không vượt quota Textract hoặc Lambda.
- Khởi chạy Distributed Map để xử lý song song các tài liệu.
-
Distributed Map quan trọng vì nó giúp chạy nhiều luồng con riêng biệt, dễ theo dõi và kiểm soát rủi ro.
3) Luồng con xử lý từng tài liệu
Các bước core gồm:
-
Xác thực tài liệu
Kiểm tra loại file, tồn tại bucket/key, metadata, mã idempotency. -
Khởi động Textract theo bất đồng bộ (
StartDocumentAnalysis)
Lấy JobId và lưu thông tin audit. -
Chờ hoàn thành bằng cách polling trạng thái hoặc dùng callback SNS khi có sự kiện.
-
Lấy kết quả tuần tự (paginated) cua Textract.
-
Chuẩn hóa và enrich dữ liệu chuyển dữ liệu thô thành định dạng JSON theo ngành, đánh giá độ tin cậy, áp dụng quy tắc nghiệp vụ.
-
Lưu kết quả:
- Kết quả thô Textract.
- Kết quả chuẩn hóa.
- Báo cáo tóm tắt.
- Bản ghi audit.
-
Đánh giá thủ công (nếu cần):
Dừng luồng vớiwaitForTaskToken, gửi thông tin cho reviewer, chờ phản hồi, sau đó tiếp tục hoặc hủy qua API. -
Đẩy event hoàn thành lên EventBridge.
4) Quản lý Textract bất đồng bộ
-
Phương pháp được dùng trong ví dụ: Step Functions polling đều đặn kiểm tra trạng thái (
GetDocumentAnalysis). -
Ưu điểm dễ triển khai, linh hoạt, phù hợp demo và nhiều trường hợp thực tế.
-
Cách nâng cao: sử dụng SNS/SQS callback để tránh polling quá nhiều, tiết kiệm tài nguyên.
5) Lưu trữ kết quả & audit
Giữ nhiều lớp dữ liệu:
- Tài liệu gốc (immutable) trong bucket
raw/. - Kết quả Textract thô trong bucket riêng (dưới dạng JSON).
- Kết quả chuẩn hóa cho downstream tiêu dùng.
- Bản ghi audit lưu trên DynamoDB, ghi nhận chi tiết từng trạng thái, JobId, thời gian, người review...
Bản ghi audit giúp tăng khả năng truy xuất, khắc phục lỗi và đảm bảo tuân thủ.
6) Bước đánh giá thủ công
- Kích hoạt khi độ tin cậy của dữ liệu thấp hoặc dữ liệu không hợp lệ.
- Luồng dừng chờ reviewer xử lý.
- Reviewer có thể chỉnh sửa, duyệt hoặc từ chối tài liệu qua API.
- Luồng Step Functions tiếp tục với kết quả do reviewer quyết định.
7) EventBridge cho tích hợp linh hoạt
- EventBridge dùng để nhận sự kiện tạo tài liệu mới và phát sự kiện khi xử lý xong.
- Các hệ thống khác (phân tích, search, notification, case management...) đăng ký riêng rẽ không phụ thuộc tight-coupling.
Tối ưu chi phí và hiệu năng
- Chọn loại workflow Step Functions phù hợp: Standard cho xử lý dài hạn, callback, retry; Express cho các luồng nhẹ.
- Giới hạn concurrency trong Distributed Map để tránh vượt quota AWS.
- Giảm polling không cần thiết bằng backoff tuần tự hoặc callback.
- Lưu trữ kết quả để tái sử dụng, tránh phải chạy Textract lại nhiều lần.
- Phân luồng xử lý thường xuyên và luồng review thủ công để kiểm soát chi phí.
Bảo mật & vận hành
- Phân quyền IAM theo nguyên tắc least privilege cho từng thành phần.
- Mã hóa vùng lưu trữ (S3, DynamoDB).
- Kiểm soát truy cập dựa trên tenant.
- Giảm logging thông tin nhạy cảm.
- Các chỉ số giám sát trạng thái, lỗi, tần suất đánh giá thủ công...
Gợi ý demo
- Chuẩn bị 1 tài liệu sạch (không cần review).
- 1 tài liệu scan kém cho bước review.
- 1 batch nhỏ để demo Distributed Map mở rộng.
Các mở rộng có thể thêm
- Phân loại tài liệu trước khi chạy Textract.
- Kiểm tra schema từng loại tài liệu.
- Mở rộng indexing với OpenSearch.
- Phân tích entity hậu xử lý với Comprehend hay Bedrock.
- Tùy chỉnh cấu hình theo tenant.
- Công cụ replay xử lý lại theo checkpoints audit.
Kết luận
Kiến trúc này không chỉ là một demo thử OCR mà còn là một quy trình xử lý tài liệu toàn diện, có khả năng mở rộng, dễ audit và linh hoạt tích hợp. Các dịch vụ AWS được kết hợp hài hòa cho một hệ thống sản xuất thực thụ.
Với những doanh nghiệp tại Việt Nam có nhu cầu số hóa tài liệu, quản lý hóa đơn, hợp đồng, form,... pipeline này là nền tảng vững chắc để phát triển hệ thống thông minh xử lý tài liệu tự động.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026