
Xây dựng và Triển khai Hệ thống Gợi ý Đa phương thức trên Amazon EKS
Bài viết này hướng dẫn quy trình thực tế xây dựng một hệ thống gợi ý đa giai đoạn, đa phương thức trên Amazon EKS. Chúng ta sẽ đi sâu vào các khâu từ xử lý dữ liệu, huấn luyện mô hình, sử dụng bộ lọc Bloom, bộ nhớ đệm tính năng cho đến xếp hạng thời gian thực.
Xây dựng và Triển khai Hệ thống Gợi ý Đa phương thức trên Amazon EKS
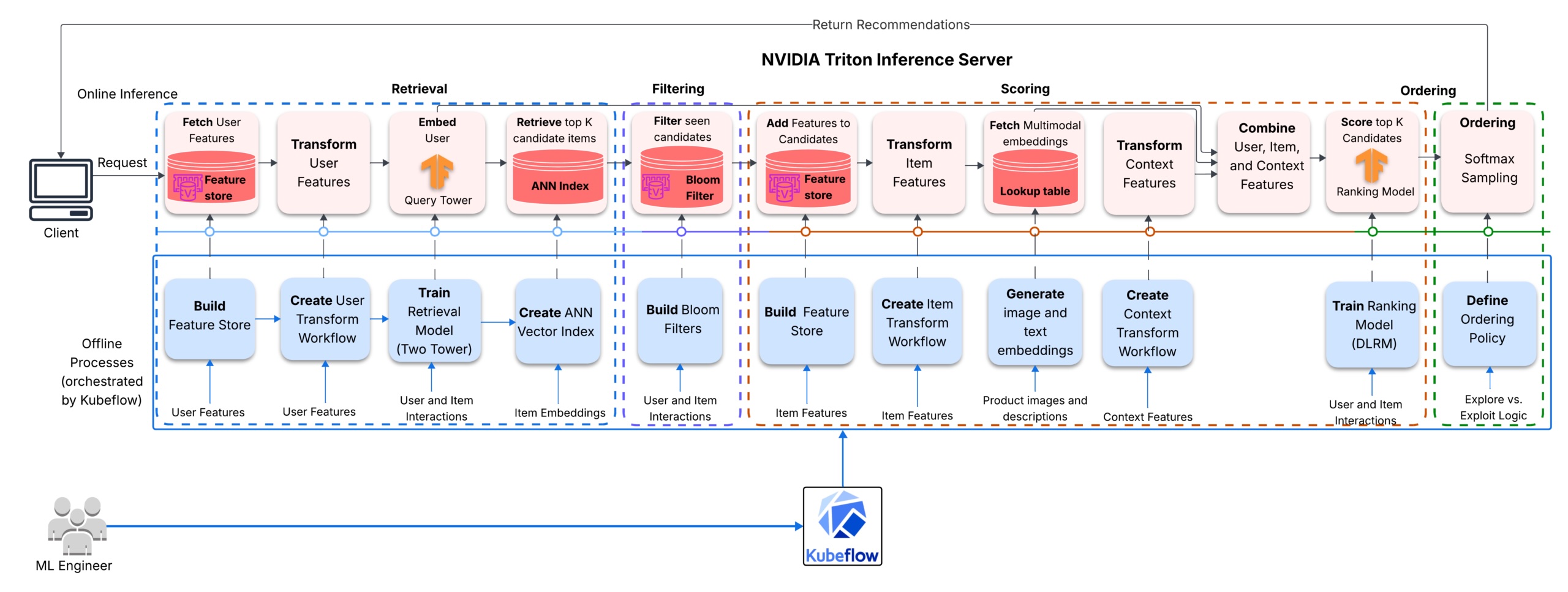
Việc xây dựng một hệ thống gợi ý (recommender system) sản phẩm đa giai đoạn và đa phương thức trong môi trường thực tế (production) là một thách thức lớn, đặc biệt khi hệ thống cần mở rộng quy mô, thích ứng gần như thời gian thực và vận hành ổn định trên đám mây. Trong bài viết này, tôi sẽ chia sẻ kinh nghiệm thiết kế và triển khai một hệ thống như vậy từ đầu đến cuối trên Amazon Elastic Kubernetes Service (EKS), bao gồm từ khâu chuẩn bị dữ liệu, huấn luyện mô hình cho đến phục vụ mô hình trong môi trường sản xuất.
Chúng ta sẽ khám phá toàn bộ quy trình pipeline bao gồm truy xuất (retrieval), lọc (filtering), chấm điểm (scoring) và xếp hạng (ranking), cùng với cơ sở hạ tầng và các quyết định quan trọng giúp hệ thống vận hành trơn tru. Điều này bao gồm việc sử dụng Feature Store, bộ lọc Bloom, Kubeflow, khả năng thích nghi sở thích gần thời gian thực và một cải tiến lớn về độ trễ nhờ bộ nhớ đệm tính năng trong RAM (in-memory feature caching).
 Tổng quan hệ thống
Tổng quan hệ thống
Tổng quan về hệ thống
Hệ thống gợi ý này bao gồm bốn giai đoạn chính:
- Mô hình Two-Tower: Tạo ra các ứng viên (candidates) tiềm năng.
- Bộ lọc Bloom: Tạm thời ẩn các mục mà người dùng vừa tương tác để tránh lặp lại.
- Mô hình xếp hạng DLRM: Chấm điểm các mục còn lại dựa trên tính năng người dùng, mục và ngữ cảnh.
- Giai đoạn xếp hạng lại (Reranking): Sắp xếp và lấy mẫu từ các điểm số này để tạo ra danh sách gợi ý cuối cùng.
Các mô hình sử dụng cả tính năng cộng tác dạng bảng (tabular collaborative features) và các vector nhúng (embeddings) hình ảnh được tính toán trước bằng CLIP cũng như vector nhúng văn bản bằng Sentence-BERT. Điều này cho phép hệ thống hiểu được cả nội dung sản phẩm và hành vi người dùng.
Tại sao chọn thiết kế này?
Trường hợp sử dụng mục tiêu là một nền tảng thương mại điện tử cần gợi ý sản phẩm liên quan ngay khi người dùng truy cập vào trang chủ. Nền tảng phục vụ cả người dùng đã đăng ký và khách vãng lai, trong khi hành vi người dùng có thể thay đổi đáng kể tùy theo ngữ cảnh yêu cầu, chẳng hạn như loại thiết bị, thời gian trong ngày hoặc ngày trong tuần.
Do đó, dịch vụ gợi ý phải cung cấp các đề xuất khả dụng cho người dùng mới (cold-start) và phải thích ứng đề xuất với ngữ cảnh của yêu cầu hiện tại. Ngoài ra, giải pháp cần khả năng mở rộng; khi danh mục sản phẩm tăng lên hàng triệu mục, việc chấm điểm toàn bộ danh mục cho mỗi yêu cầu là không khả thi. Thiết kế đa giai đoạn giải quyết vấn đề này bằng cách sử dụng giai đoạn truy xuất nhẹ để nhanh chóng tìm kiếm ứng viên và giai đoạn xếp hạng nặng hơn để chấm điểm những ứng viên đó.
Các thành phần hệ thống và Công nghệ
Tất cả các thành phần hoạt động cùng nhau để đảm bảo mục tiêu tổng thể là phục vụ các gợi ý liên quan nhanh chóng và ở quy mô hợp lý.
- Kubeflow Pipelines: Quản lý quy trình làm việc huấn luyện đầy đủ và quy trình tinh chỉnh hàng ngày trên hệ thống dựa trên Kubernetes.
- NVIDIA Merlin Stack: Xử lý kỹ thuật tính năng tăng tốc GPU, tiền xử lý, huấn luyện các mô hình truy xuất và xếp hạng.
- NVIDIA Triton Inference Server: Lưu trữ đồ thị phục vụ đa giai đoạn dưới dạng một mô hình ensemble duy nhất.
- FAISS: Đóng vai trò là chỉ số láng giềng gần nhất xấp xỉ (ANN index) để truy xuất ứng viên.
- Feast & ElastiCache for Valkey (Redis): Quản lý tính năng người dùng và mục. ElastiCache quản lý bộ lọc Bloom của từng người dùng để lọc các mục đã xem và lưu trữ thông tin phổ biến của mục.
- Amazon EKS: Chạy các quy trình máy học được đóng container và tự động mở rộng tính toán để đáp ứng nhu cầu thay đổi.
Quy trình huấn luyện và Triển khai
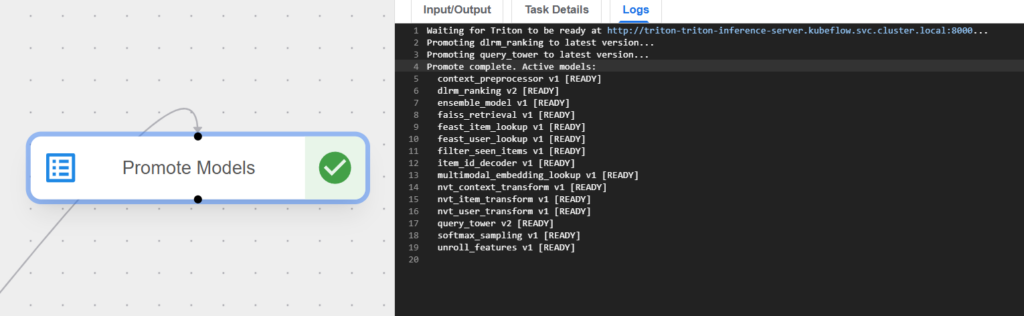
Hệ thống sử dụng hai pipeline Kubeflow riêng biệt. Pipeline đầu tiên thiết lập các quy trình tiền xử lý, huấn luyện các mô hình từ đầu, xây dựng chỉ số ANN và triển khai máy chủ Triton. Pipeline thứ hai quản lý việc tinh chỉnh hàng ngày, chủ yếu cập nhật tháp truy vấn (query tower) và bộ xếp hạng; các mô hình được cập nhật với các tín hiệu tương tác mới nhưng không tạo lại các vector nhúng mục.
 Pipeline Kubeflow
Pipeline Kubeflow
Trong quá trình huấn luyện, dữ liệu được giả lập để xử lý tình huống cold-start bằng cách thay thế một phần nhỏ tính năng người dùng bằng các giá trị sentinel. Điều này buộc mô hình phải học cách dựa vào các tín hiệu ngữ cảnh khi gặp người dùng mới.
Xử lý yêu cầu và Tối ưu hóa độ trễ
Máy chủ Triton chứa 14 mô hình trên hai backend (Python và TensorFlow). Một cấu hình ensemble kết nối tất cả các mô hình này thành một đồ thị có hướng vô hướng (DAG) mà Triton thực thi.
Khi xử lý yêu cầu, hệ thống sẽ tìm kiếm tính năng người dùng từ kho tính năng trực tuyến (online feature store). Nếu người dùng không được tìm thấy, hệ thống sử dụng các giá trị mặc định để xử lý cold-start. Sau đó, mô hình Two-Tower tạo ra vector nhúng người dùng và FAISS thực hiện tìm kiếm tương đồng để trả về các ID mục hàng đầu.
Các ID mục này được kiểm tra thông qua bộ lọc Bloom trong ElastiCache để loại bỏ các mục đã xem. Cuối cùng, mô hình DLRM chấm điểm các ứng viên và một bước lấy mẫu softmax (nếu bật chế độ đa dạng) sẽ xác định danh sách cuối cùng.
Cải thiện độ trễ với bộ nhớ đệm trong RAM (In-memory Caching)
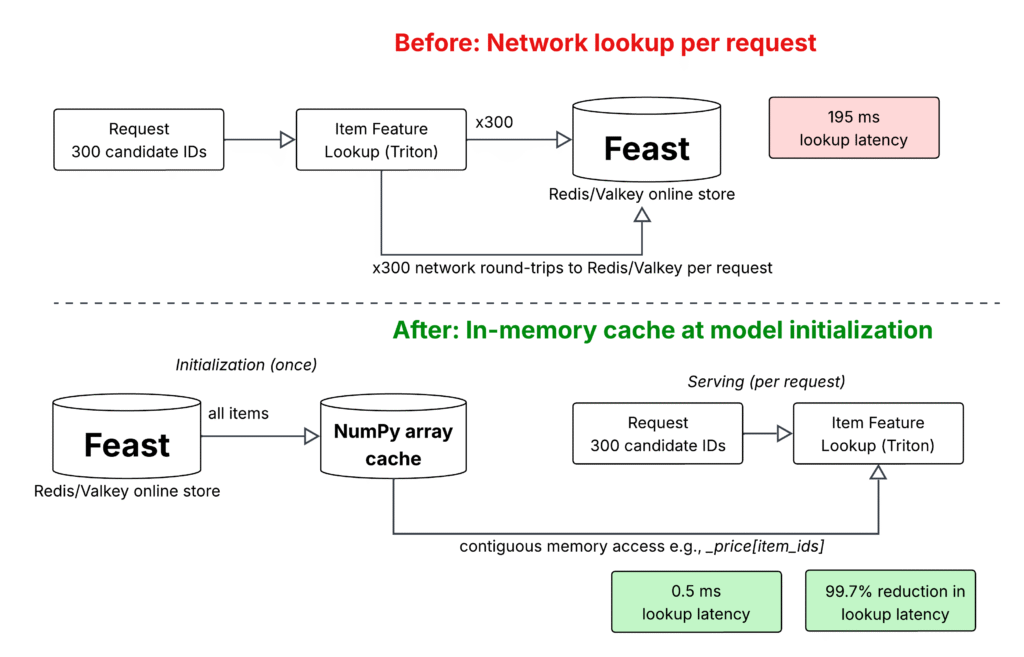
Một trong những bài toán quan trọng là tối ưu hóa hiệu suất. Phân tích hồ sơ máy chủ cho thấy feast_item_lookup tiêu tốn 195ms, chiếm khoảng 52% tổng độ trễ yêu cầu. Nút thắt cổ chai là do việc tìm kiếm tính năng cho 300 ứng viên từ kho trực tuyến của Feast trên mỗi yêu cầu.
 Biểu đồ độ trễ
Biểu đồ độ trễ
Để giải quyết vấn đề này, các cuộc gọi Feast cho tính năng mục đã được thay thế bằng bộ nhớ đệm mảng NumPy trong quy trình (in-process). Về cơ bản, tại thời điểm khởi tạo, tất cả tính năng mục được tìm nạp một lần từ Feast và lưu trữ dưới dạng mảng NumPy được lập chỉ mục theo ID mục. Mọi yêu cầu sau đó sẽ đọc tính năng từ bộ nhớ thay vì thực hiện cuộc gọi mạng đến kho trực tuyến.
Sự tối ưu hóa này đã mang lại cải thiện khoảng 99,7% về độ trễ của feast_item_lookup và cải thiện 54% về độ trễ đầu cuối. Thông lượng (throughput) cũng được cải thiện 310%.
Tự động mở rộng trên EKS
Máy chủ Triton Inference Server được tự động mở rộng thông qua Kubernetes Horizontal Pod Autoscaler (HPA) dựa trên một chỉ số tùy chỉnh — thời gian trung bình (tính bằng mili-giây) mà mỗi yêu cầu dành để chờ trong hàng đợi trong 30 giây qua. Khi độ trễ này vượt quá mục tiêu, HPA sẽ mở rộng triển khai Triton.
Nếu không thể lên lịch pod Triton mới do không có nút GPU nào còn dung lượng, Karpenter sẽ cung cấp một nút GPU mới và thêm nó vào cụm. Điều này đảm bảo hệ thống luôn đáp ứng được nhu cầu tải cao.
Kết luận
Bài viết này đã đi qua một hệ thống gợi ý đa giai đoạn, đa phương thức cho trường hợp sử dụng thương mại điện tử, được triển khai trên Amazon EKS. Hệ thống kết hợp truy xuất ứng viên Two-Tower, xếp hạng DLRM nhận biết ngữ cảnh và xếp hạng đa dạng dựa trên điểm số.
Vấn đề cold-start được giải quyết thông qua việc che tính năng trong quá trình huấn luyện, buộc các mô hình phải dựa vào vector nhúng OOV đã học và tín hiệu ngữ cảnh khi người dùng mới hoặc ẩn danh. Bộ lọc Bloom ngăn các mục đã xem xuất hiện lại, và bộ nhớ đệm tính năng trong RAM đã giúp giải quyết nút thắt cổ chai về độ trễ. Về phía MLOps, hai pipeline Kubeflow quản lý vòng đời của hệ thống, cho phép cập nhật mô hình hàng ngày mà không cần xây dựng lại chỉ số nhúng mục.
Đây là một ví dụ điển hình về hệ thống gợi ý kiểu sản xuất, trong đó giai đoạn truy xuất được tối ưu hóa cho tốc độ và độ phủ kết hợp với giai đoạn xếp hạng được tối ưu hóa cho độ chính xác.
Bài viết liên quan

Công nghệ
Anthropic bắt tay TCS để thúc đẩy triển khai AI trong doanh nghiệp
11 tháng 6, 2026
Công nghệ
Người Mỹ không thể nhận diện deepfake: Đây là cuộc khủng hoảng doanh nghiệp chứ không chỉ là vấn đề truyền thông
21 tháng 5, 2026
AI & ML
TrustCloud: Giải pháp thay thế bảng câu hỏi thủ công bằng tự động hóa đánh giá ứng dụng cho CISO
16 tháng 6, 2026