
C++ Neoclassical: Tái chiêm nghiệm Segmented Iterators và hiệu năng vượt trội
Bài viết xem lại khái niệm "segmented iterators" từng được đề xuất từ năm 2000 nhằm loại bỏ chi phí trừu tượng trong C++. Thông qua các thử nghiệm mới của Boost.Container, chúng ta thấy những cải thiện hiệu năng ấn tượng (có trường hợp tăng gấp 17 lần) so với thư viện chuẩn hiện nay nhờ tận dụng cấu trúc phân đoạn của dữ liệu.

Thư viện STL (Standard Template Library) huyền thoại luôn là nguồn cảm hứng bất tận cho sự phát triển của ngôn ngữ và thư viện C++. Những tư duy về khái niệm (concept) và mã nguồn do Stepanov, Lee, Musser, Austern và các đồng nghiệp xây dựng là kho tàng quý giá cho bất kỳ lập trình viên C++ nào.
Tuyên bố cốt lõi của Stepanov là sự trừu tượng hóa phải có chi phí gần như bằng không (near-zero overhead). Ông lập luận rằng lập trình hướng generic, nếu thực hiện đúng, không nên gây ra chi phí thời gian chạy đáng chú ý (abstraction penalty) so với mã chuyên biệt viết tay. Đây không chỉ là hy vọng mà còn là nguyên tắc thiết kế của STL.
Tiếp nối triết lý này, vào năm 2000, Matt Austern đã xuất bản bài báo quan trọng mang tên Segmented Iterators and Hierarchical Algorithms. Lập luận chính của bài báo là nhiều cấu trúc dữ liệu tự nhiên có tính phân đoạn (segmented), ví dụ như std::deque. Các thuật toán generic bỏ qua đặc điểm này — coi mọi cấu trúc dữ liệu như một dải phần tử đồng nhất — sẽ không cần thiết kém hiệu quả.
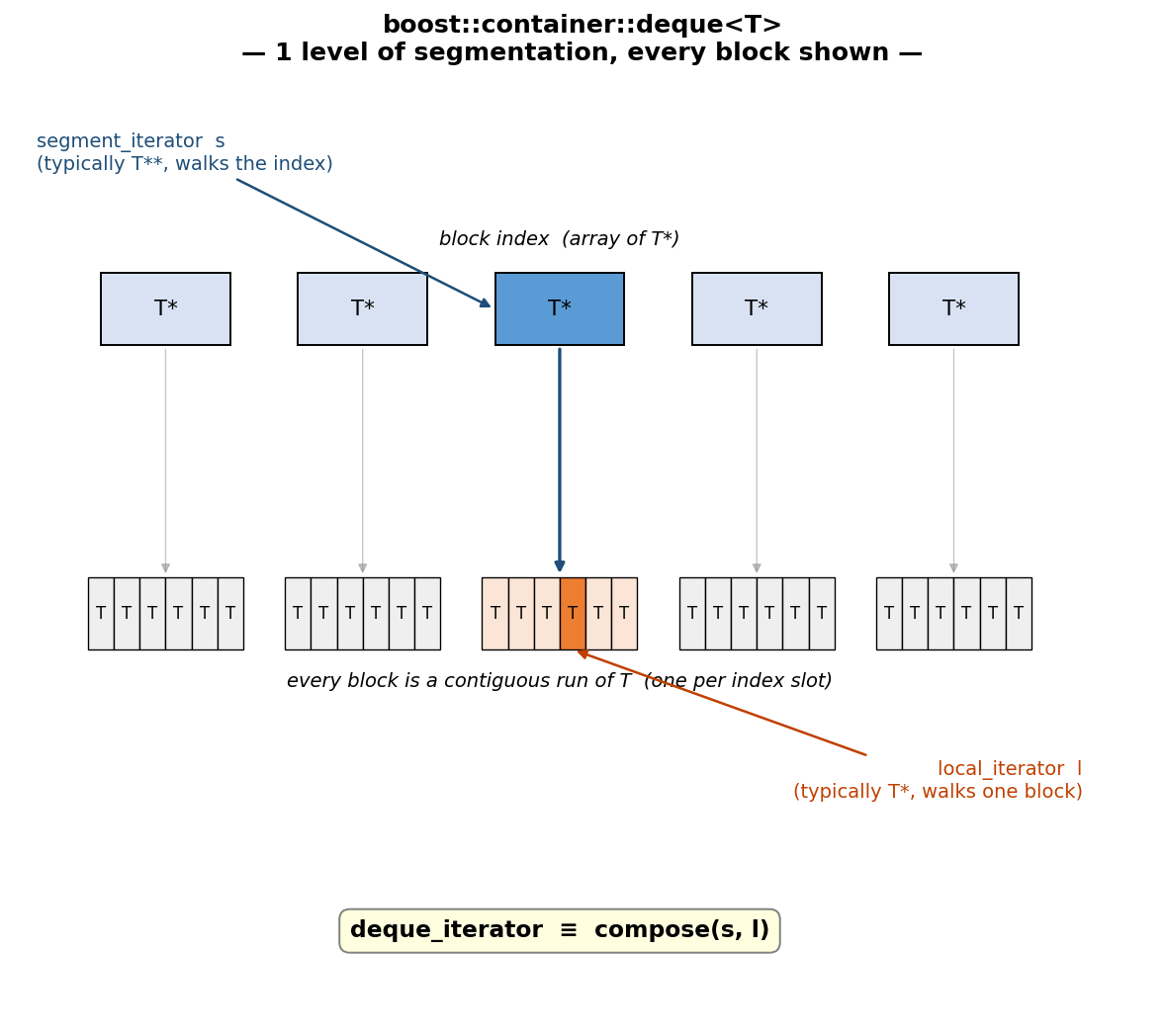 Cấu trúc phân đoạn của deque
Cấu trúc phân đoạn của deque
Vấn đề của Iterator chuẩn
Ví dụ kinh điển là std::deque. Bên trong, nó thực chất là một chuỗi các mảng có kích thước cố định. Mỗi thao tác ++it trên iterator của deque có thể vượt qua ranh giới khối (block boundary). Do đó, các thuật toán như std::find hay std::fill phải ngầm ước lượng ở mỗi bước xem con trỏ hiện tại đã chạm đến cuối khối hiện tại chưa. Sự gián tiếp này làm cho việc lặp qua deque trở nên chậm hơn đo được và cũng làm vô hiệu hóa khả năng tự động vector hóa (auto-vectorisers) của hầu hết các trình biên dịch.
Một segmented iterator có thể là một cấu trúc hai cấp, cho phép thuật toán hoạt động hiệu quả trên từng đoạn liền kề (ví dụ: gọi memset hoặc vòng lặp nội bộ chặt chẽ trên từng khối) và chỉ xử lý chuyển đổi giữa các đoạn ở vòng lặp ngoài.
Bài báo của Austern vẫn rất có ảnh hưởng nhưng các ý tưởng của nó chưa từng được đưa vào tiêu chuẩn C++. Tuy nhiên, một số thư viện đã phát triển nội bộ những ý tưởng cốt lõi này. Khoảng năm 2023, std::for_each trong libc++ đã được tối ưu hóa cho segmented iterators, dẫn đến cải thiện hiệu suất cao.
Khái niệm Segmented Iterators giải thích
Một iterator truyền thống cung cấp cái nhìn phẳng: tăng, giảm, giải tham chiếu. Một segmented iterator thêm khả năng phân tách thành hai tọa độ:
- segment_iterator: Duyệt qua chuỗi các phân đoạn bên ngoài (các khối của deque, các chunk của chunk-list...). Iterator này không thể giải tham chiếu.
- local_iterator: Duyệt qua phạm vi bên trong một phân đoạn. Iterator này có thể giải tham chiếu và hiệu quả cao.
Một thuật toán phân cấp (hierarchical algorithm) khi nhận được một segmented iterator sẽ chuyển sang một vòng lặp hai cấp: vòng lặp ngoài qua các phân đoạn và bên trong mỗi phân đoạn là một thuật toán đơn giản hóa trên local_iterator hiệu quả cao.
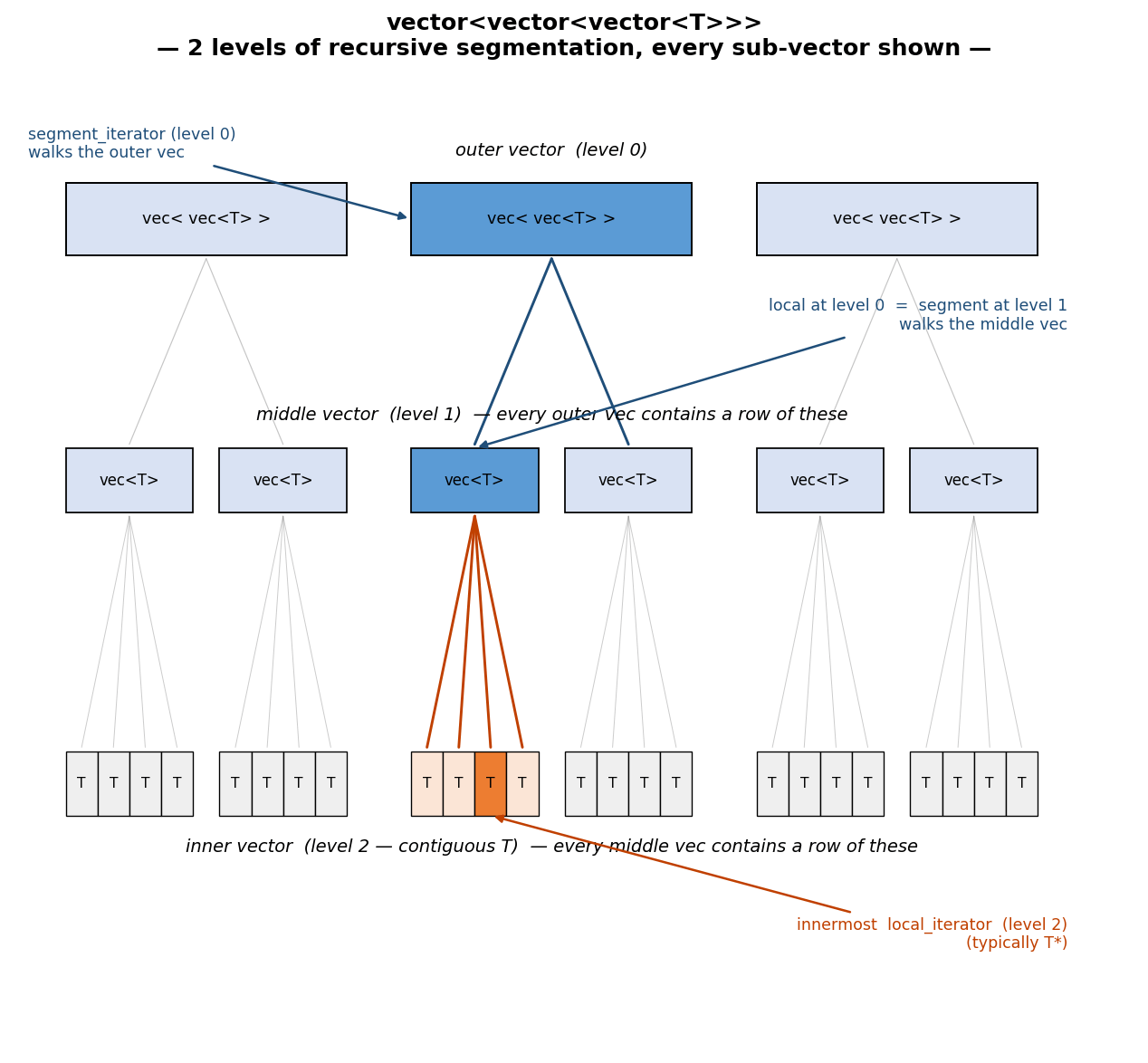 Cấu trúc phân đoạn lồng nhau
Cấu trúc phân đoạn lồng nhau
Austern đề xuất lớp segmented_iterator_traits để xác định các nguyên thủy cho các thuật toán nhận biết phân đoạn, bao gồm các hàm như segment(), local(), begin(), end()...
Với cơ chế đó, thuật toán fill trên một phạm vi phân đoạn được viết thành một hành trình gồm ba phần: đuôi của phân đoạn đầu tiên, toàn bộ các phân đoạn giữa, và đầu của phân đoạn cuối cùng. Các lệnh gọi std::fill này là các vòng lặp phẳng trên local_iterator, có thể hiệu quả tương đương với con trỏ T*. Bài báo của Austern tuyên bố rằng có thể đạt được cải thiện hiệu suất khoảng 20% so với việc triển khai STL truyền thống.
Tuy nhiên, chúng ta sẽ thấy rằng với các trình biên dịch hiện đại, một local_iterator hiệu quả có thể mang lại mức hiệu quả cao hơn nhiều.
Thử nghiệm tại Boost.Container
Boost.Container đã bắt đầu công việc thử nghiệm trên các thuật toán phân đoạn, tuân theo chặt chẽ đề xuất ban đầu. Mục tiêu là xem nỗ lực này sẽ dẫn đến một đề xuất thư viện Boost mới hay chỉ là chi tiết triển khai để tăng tốc cho các cấu trúc dữ liệu phân đoạn như deque, hub...
Mã nguồn thử nghiệm hiện có thể tìm thấy trong kho lưu trữ Boost.Container. Các thuật toán được triển khai để:
- Phân loại dựa trên
segmented_iterator_traits::is_segmented_iterator. - Khi iterator được phát hiện là phân đoạn, thuật toán sẽ phân giải phạm vi đầu vào thành phân đoạn đầu, giữa và cuối, gọi đệ quy chính nó trên từng phần, và cuối cùng chạm đến đáy là một vòng lặp phẳng trên kiểu
local_iterator. - Khi không phải phân đoạn, thuật toán sẽ suy sụp thành vòng lặp kinh điển giống như phiên bản thư viện chuẩn.
Benchmark ấn tượng trên các trình biên dịch hiện đại
Mục tiêu của bài viết này là hiển thị hiệu suất của các thuật toán phân đoạn thử nghiệm này, bắt đầu với container boost::container::deque kinh điển. Trong bài kiểm tra, deque được triển khai với kích thước khối cố định là 128 phần tử.
Các bài kiểm tra chạy trên nhiều trình biên dịch: MSVC 2022/2026, GCC 16, Clang 22 với libstdc++ và libc++. Các thuật toán bao gồm fill, find, count, for_each, v.v.
Kết quả cấu hình A: Không gợi ý unroll (No unroll hint)
Trong cấu hình này, thuật toán phân đoạn và vòng lặp cục bộ không sử dụng #pragma unroll. Kết quả là rất đáng kinh ngạc.
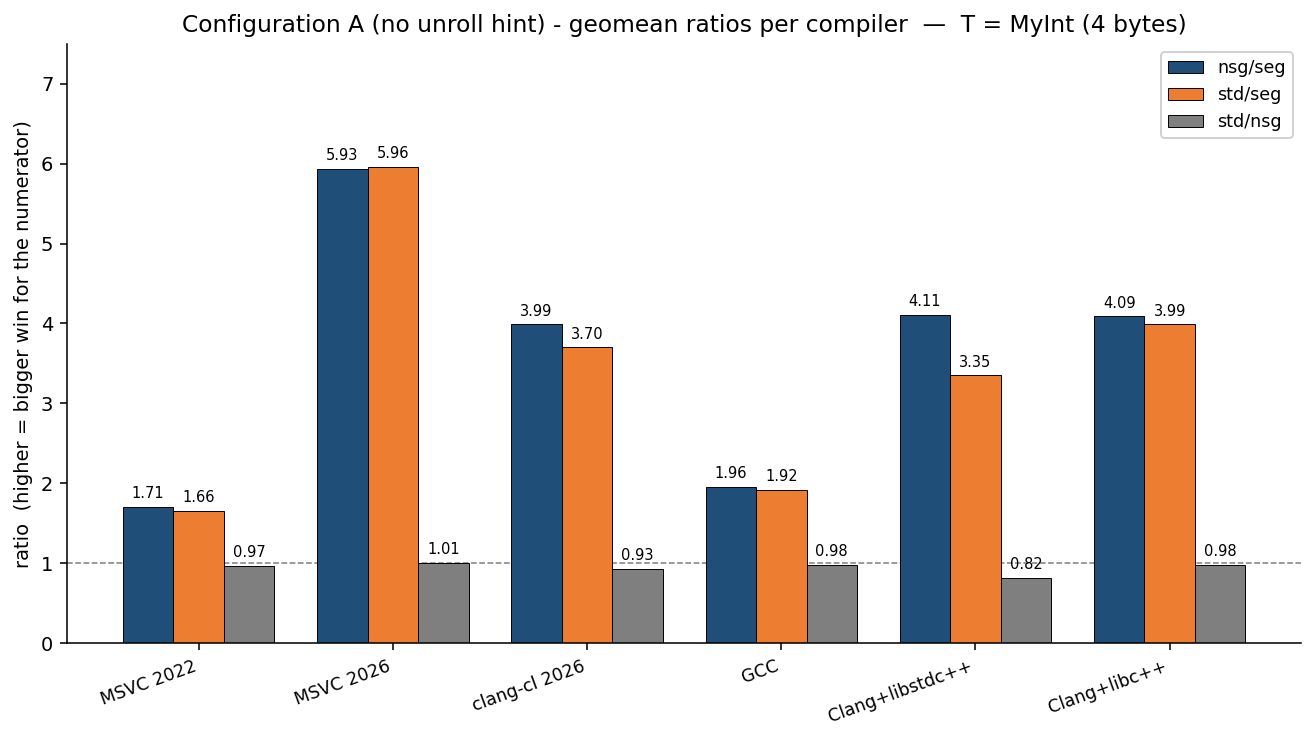
Đối với kiểu dữ liệu nhỏ (MyInt 4 bytes):
- MSVC 2026: Thuật toán phân đoạn chạy nhanh hơn 5.96 lần so với thuật toán chuẩn (
std) và 5.93 lần so với đường rơi không phân đoạn. - Clang: Cũng đạt mức tăng trưởng từ 3.35 đến 3.99 lần.
 Biểu đồ kết quả MyInt Config A
Biểu đồ kết quả MyInt Config A
Điều này cho thấy sự khác biệt lớn giữa các trình biên dịch. Các thuật toán phân đoạn đạt được mức tăng hiệu suất tốt đến tuyệt vời, cao hơn nhiều so với kết quả Austern đo được vào năm 2000. Có lẽ sự thay đổi của kiến trúc bộ vi xử lý và bộ nhớ đã làm tăng khoảng cách giữa vòng lặp phẳng và vòng lặp phân đoạn.
Cụ thể, trên MSVC 2026, thuật toán fill đạt tốc độ nhanh hơn 17 lần so với đường không phân đoạn. Đây là ví dụ kinh điển của SIMD store: vòng lặp nội bộ phân đoạn là T* ghi một hằng số vào một số lượng int liền kề đã biết, được hạ cấp thành các lưu trữ rộng (wide stores). Phiên bản không phân đoạn không thể chứng minh vòng lặp đi qua một vùng đệm liền kề và tạo ra mã assembly vô hướng.
Biểu đồ kết quả MyFatInt Config A
Kết quả cấu hình B: Có gợi ý Inner-loop unroll
Khi thêm #pragma unroll(4) vào vòng lặp nội bộ, bức tranh thay đổi rất khác:
- MSVC: Về bản chất bỏ qua gợi ý này.
- GCC 16: Đây là bất ngờ. Gợi ý này giúp ích rất nhiều. Tỷ lệ
nsg/segtăng từ 1.96× lên 3.13× trênMyInt. - Clang: Thực sự bị giảm hiệu suất (regress) trên
MyInt. Có vẻ như việc unroll thủ công can thiệp vào bộ tối ưu hóa của trình biên dịch.
Trong các bài kiểm tra này, việc unroll chỉ giúp GCC và làm giảm hiệu năng Clang, do đó việc triển khai di động nên tránh unroll thủ công trên Clang.
Kết luận
Chúng ta có thể tóm tắt các bài kiểm tra thuật toán segmented-iterator trên deque trong ba phát hiện chính:
- Hiệu suất vượt trội: Đối với các thuật toán đơn lượt, thuật toán phân đoạn có thể mang lại tốc độ tăng lớn (trung bình 5.93 lần nhanh hơn trên MSVC 2026), với mức tăng khổng lồ (17x) trong một số trường hợp cụ thể. Các trình biên dịch ngày càng tốt hơn trong việc tận dụng các thuật toán phân đoạn khi
local_iteratorcó thể được đơn giản hóa thành con trỏ thô. - Thư viện chuẩn: Hiệu suất của thư viện chuẩn tương tự như thuật toán Boost không phân đoạn và không phụ thuộc vào trình biên dịch.
- Unroll hints hỗn hợp: Đây là con dao hai lưỡi. MSVC hiện đại thờ ơ, GCC 16 được hưởng lợi, còn Clang thì bị thụt lùi. Mặc định đúng do đó phụ thuộc vào trình biên dịch.
Ít có điều gì trong lĩnh vực của chúng ta già đi một cách thanh lịch như một bài báo nêu ra một sự thật cấu trúc và để các thế hệ sau bắt kịp nó. Segmented Iterators and Hierarchical Algorithms của Matt Austern là một trong những bài báo như vậy. Nó đã xác định một sự không khớp và đề xuất một kỹ thuật đủ thanh lịch để vẫn cảm thấy hiện đại sau một phần tư thế kỷ.
Đó chính là món quà mà một sự trừu tượng hóa đúng đắn mang lại cho bạn: nó già đi cùng với các cải tiến phần cứng thay vì đi ngược lại nó. Đây cũng là lời nhắc nhở rằng việc xem lại các tài liệu C++ kinh điển — Stepanov, Austern, Musser, Lee — hiếm khi chỉ là một bài tập hoài niệm.
Bài viết liên quan

Công nghệ
AI tác nhân: Hype tăng nhiệt nhưng doanh nghiệp vẫn loay hoay ở giai đoạn thí điểm
05 tháng 6, 2026

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026