
Dự đoán World Cup 2026 với 11 mô hình Machine Learning: Khi sự bất đồng quan trọng hơn sự đồng thuận
Thay vì tin vào một con số duy nhất, tác giả đã xây dựng 11 mô hình Machine Learning khác nhau để dự đoán kết quả World Cup 2026. Sự bất đồng giữa các mô hình — với 4 nhà vô địch khác nhau được chọn ra — mới chính là thông tin có giá trị nhất, giúp hiểu rõ hơn về sự bất định của dữ liệu.

Dự đoán World Cup 2026 với 11 mô hình Machine Learning: Khi sự bất đồng quan trọng hơn sự đồng thuận
Có 48 đội tuyển tham dự World Cup 2026, 104 trận đấu và khoảng chừng đó dự đoán tự tin ngang bằng số lượng người hâm mộ. Việc xây dựng một mô hình tuyên bố "Đội X thắng với xác suất p" là điều dễ dàng — chỉ mất một buổi chiều với dữ liệu công cộng và phân phối Poisson. Cái bẫy nằm ở chỗ tin vào con số đó. Một mô hình đơn lẻ chỉ cho bạn một câu trả lời duy nhất mà không cho bạn biết nó phụ thuộc bao nhiêu vào hàng chục lựa chọn được chôn giấu bên trong: hệ thống xếp hạng nào, mô hình bàn thắng nào, thuật toán học máy nào. Thay đổi bất kỳ cái nào trong số đó, "câu trả lời" có thể dao động hai con số.
Thay vì tin tưởng một mô hình, tôi đã xây dựng mười một mô hình — một cho (gần như) mọi chương của một giáo trình Machine Learning — huấn luyện hoặc tính toán tất cả chúng trên cùng một dữ liệu trận đấu thực tế, chạy từng mô hình qua cùng một bộ mô phỏng giải đấu, và để chúng tranh luận. Ba hệ thống xếp hạng (Elo, Colley, PageRank), hai mô hình bàn thắng (Poisson, Negative Binomial), năm bộ phân loại (hồi quy logistic, KNN, rừng ngẫu nhiên, XGBoost, mạng nơ-ron) và thị trường cá cược làm thước đo chuẩn. Cùng 48 đội tuyển, cùng dữ liệu, mười một phương pháp.
Chúng trao vương miện cho bốn nhà vô địch khác nhau — và sự bất đồng đó, không phải sự đồng thuận, hóa ra lại là điều hữu ích nhất mà một bộ mô hình có thể mang lại. Bài viết này sẽ nói về cách xây dựng nó và cách đọc nó.
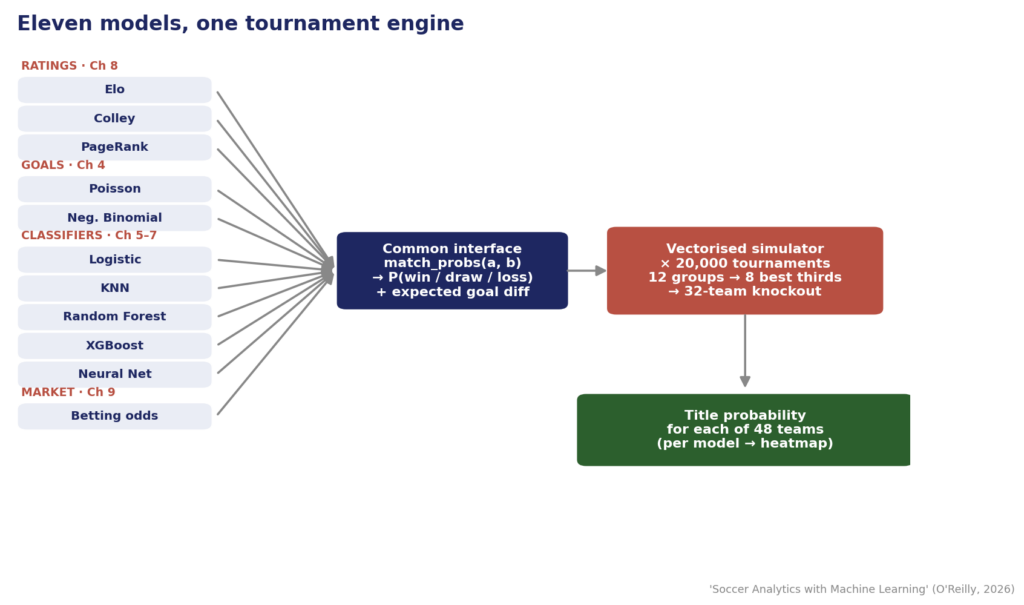 Sơ đồ tổng quan về quy trình mô hình
Sơ đồ tổng quan về quy trình mô hình
Dữ liệu
Mọi thứ đều được fit dựa trên 358 trận đấu quốc tế thực tế: mọi trận từ các World Cup 2010–2022 (256 trận) cộng với các giải Vô địch Châu Âu (Euro) 2020 và 2024 (102 trận), được lấy từ dự án openfootball. Các bộ phân loại học cách ánh xạ từ các đặc điểm của trận đấu sang kết quả trên các trận đấu này; các hệ thống xếp hạng được tính toán trực tiếp từ đồ thị kết quả. Lĩnh vực thi đấu là bảng bốc thăm thực tế đã được xác nhận của năm 2026 — 48 đội, 12 bảng.
Ba đặc điểm mô tả mỗi trận đấu dưới góc độ của đội "nhà" (đội được đặt tên đầu tiên, sân trung lập): khoảng cách sức mạnh giữa các đội, sức mạnh tổng hợp của họ và cờ đấu loại trực tiếp. Mục tiêu là kết quả ba chiều (thắng / hòa / thua).
Một giao diện, mười một động cơ
Cách duy nhất để chạy đua công bằng giữa các họ mô hình khác nhau là ép buộc chúng thông qua cùng một hợp đồng: cho hai đội, trả về P(thắng), P(hòa), P(thua) cộng với hiệu số bàn thắng kỳ vọng cho các trận đấu vòng bảng. Mọi thứ ở hạ lưu đều giống hệt nhau giữa các mô hình: 12 bảng, 8 đội đứng thứ ba tốt nhất, và vòng đấu loại trực tiếp 32 đội. Trình mô phỏng thậm chí được vector hóa để tất cả 20.000 giải đấu cho mỗi mô hình chạy dưới dạng các thao tác mảng NumPy thay vì vòng lặp Python.
Mười một mô hình cung cấp cho một động cơ giải đấu. Điều khác biệt là cách mỗi mô hình điền vào match_probs. Đó là nơi sự bất đồng sinh ra, vì vậy hãy đi qua từng họ.
Các mô hình xếp hạng: sức mạnh từ kết quả
Elo là cái mà hầu hết mọi người đã nghe nói — xếp hạng cờ vua, được điều chỉnh cho bóng đá: một số tự điều chỉnh được cập nhật sau mỗi trận đấu. Để có xác suất trận đấu, chúng ta chạy khoảng cách Elo qua đường cong logistic đó và tách riêng xác suất hòa được fit riêng (xem thêm bên dưới).
Xếp hạng Colley loại bỏ hoàn toàn việc cập nhật theo thời gian và giải một hệ thống tuyến tính đơn. Colley rất chính xác vì nó không có tham số tự do và không có khái niệm về "phong độ hiện tại": đó là bản tóm tắt dạng đóng thuần túy về ai đã thắng ai.
PageRank coi mùa giải như một đồ thị có hướng. Mỗi trận đấu thêm trọng số vào một cạnh từ đội thua sang đội thắng (hòa chia trọng số cả hai hướng), vì vậy chỉ vào một đội là sự bảo chứng. Chuẩn hóa các cạnh ra của mỗi nút thành một ma trận chuyển tiếp ngẫu nhiên, sau đó tìm phân phối tĩnh dưới một bước đi ngẫu nhiên có giảm chấn. Một đội đạt điểm cao nếu các đội mạnh "chỉ vào" nó — tức là thua nó. Đó là cùng một thuật toán mà Google từng dùng để xếp hạng các trang web, được áp dụng cho kết quả bóng đá.
Colley và PageRank sống trên thang đo riêng của chúng, vì vậy tôi chuẩn hóa z-score mỗi cái và ánh xạ lên thang đo giống Elo trước khi chạy chúng qua cùng một đường cong kỳ vọng thắng.
Các mô hình bàn thắng: Poisson và Negative Binomial
Các mô hình này mô hình hóa tỷ số, không phải kết quả. Tôi fit một mô hình Poisson GLM với liên kết log trên các bàn thắng thực tế, xếp chồng mỗi trận đấu thành hai quan sát (bàn thắng của mỗi đội so với khoảng cách sức mạnh có dấu của họ).
Từ λ_home, λ_away, chúng ta khôi phục P(W/D/L) bằng cách tạo tích ngoài của hai phân phối bàn thắng Poisson của hai đội và tổng hợp các ô mà đội nhà ghi nhiều bàn hơn, bằng nhau hoặc ít hơn đội khách.
Biến thể Negative Binomial (Nhị thức âm) nới lỏng giả định hạn chế nhất của Poisson — rằng trung bình bằng phương sai. Dữ liệu bàn thắng thực tế bị phân tán nhẹ quá mức (overdispersed), vì vậy NB giới thiệu một tham số phân tán α. Ở đây α ≈ 0.008 rất nhỏ, vì vậy NB hầu như không khác biệt so với Poisson — chính nó là một phát hiện thực nghiệm hữu ích.
Các bộ phân loại: kết quả từ đặc điểm
Năm mô hình dự đoán P(W/D/L) trực tiếp từ ba đặc điểm:
- Hồi quy Logistic: mô hình đa thức/softmax, tuyến tính trong log-odds.
- K-Láng giềng Gần nhất (KNN): không có dạng tham số nào cả; nó dự đoán một trận đấu từ sự cân bằng lớp của 30 trận đấu lịch sử gần nhất.
- Rừng Ngẫu nhiên (Random Forest): các cây quyết định được đóng gói, mỗi cây được trồng trên một mẫu bootstrap và một tập hợp con đặc điểm ngẫu nhiên, sau đó lấy trung bình.
- XGBoost: các cây tăng cường gradient, fit tuần tự để mỗi cây sửa chữa các phần dư của tập hợp trước đó.
- Mạng nơ-ron: một perceptron đa lớp nhỏ (16→8 đơn vị ẩn) tự học các tương tác đặc điểm của riêng nó.
Vấn đề về trận hòa
Một sự tinh tế liên kết các mô hình xếp hạng lại với nhau. Elo, Colley và PageRank vốn dĩ chỉ đưa ra kỳ vọng thắng, không phải sự chia ba chiều — vậy P(hòa) đến từ đâu?
Tôi fit nó từ dữ liệu dưới dạng một hàm logistic của khoảng cách sức mạnh tuyệt đối: các đội cân sức hòa nhau thường xuyên hơn nhiều so với các đội chênh lệch. Đường cong được hiệu chuẩn duy nhất này được chia sẻ bởi cả ba mô hình xếp hạng, giúp giữ cho sự so sánh công bằng.
Một trận đấu, mười một ý kiến
Trước khi mô phỏng cả một giải đấu, việc xem sự bất đồng ở cấp độ một trận đấu đơn lẻ rất có ích. Hãy lấy trận Tây Ban Nha vs Maroc — một ứng viên nặng ký chống lại một đội bóng tấm rất tốt. Dưới đây là xác suất thắng / hòa / thua mà mỗi mô hình gán cho Tây Ban Nha:
- PageRank: 69% thắng, 24% hòa, 7% thua.
- Poisson: 63% thắng, 22% hòa, 15% thua.
- Negative Binomial: 62% thắng, 22% hòa, 15% thua.
- Logistic: 61% thắng, 24% hòa, 15% thua.
- Elo: 61% thắng, 26% hòa, 13% thua.
- Colley: 57% thắng, 26% hòa, 17% thua.
- Mạng nơ-ron: 56% thắng, 20% hòa, 24% thua.
- KNN: 47% thắng, 27% hòa, 27% thua.
- Random Forest: 40% thắng, 39% hòa, 22% thua.
- XGBoost: 25% thắng, 64% hòa, 11% thua.
Xác suất thắng của Tây Ban Nha dao động từ 69% (PageRank) xuống còn 25% (XGBoost) — và XGBoost thực sự coi kết quả hòa là khả năng nhất, ở mức 64%. Đây không phải là sự khác biệt làm tròn — chúng là những lý thuyết khác nhau về cùng một trò chơi.
Kết quả: Chúng không đồng thuận
Ai sẽ thắng World Cup? Các mô hình bất đồng, nhưng nhiều điều chỉ ra Tây Ban Nha.
Dọc theo bất kỳ hàng nào, vận may của một đội tuyển dao động tùy thuộc vào ai đang hỏi. Tây Ban Nha dao động từ 13% (kẻ bị lãng quên) đến 29% (người dẫn đầu). Dòng dưới cùng — nhà vô địch có khả năng cao nhất của mỗi mô hình:
- Tây Ban Nha: Elo, Poisson, Negative Binomial, Logistic, KNN, PageRank và thị trường.
- Argentina: Random Forest, XGBoost.
- Pháp: Mạng nơ-ron.
- Hà Lan: Colley.
Mười một mô hình, bốn nhà vô địch.
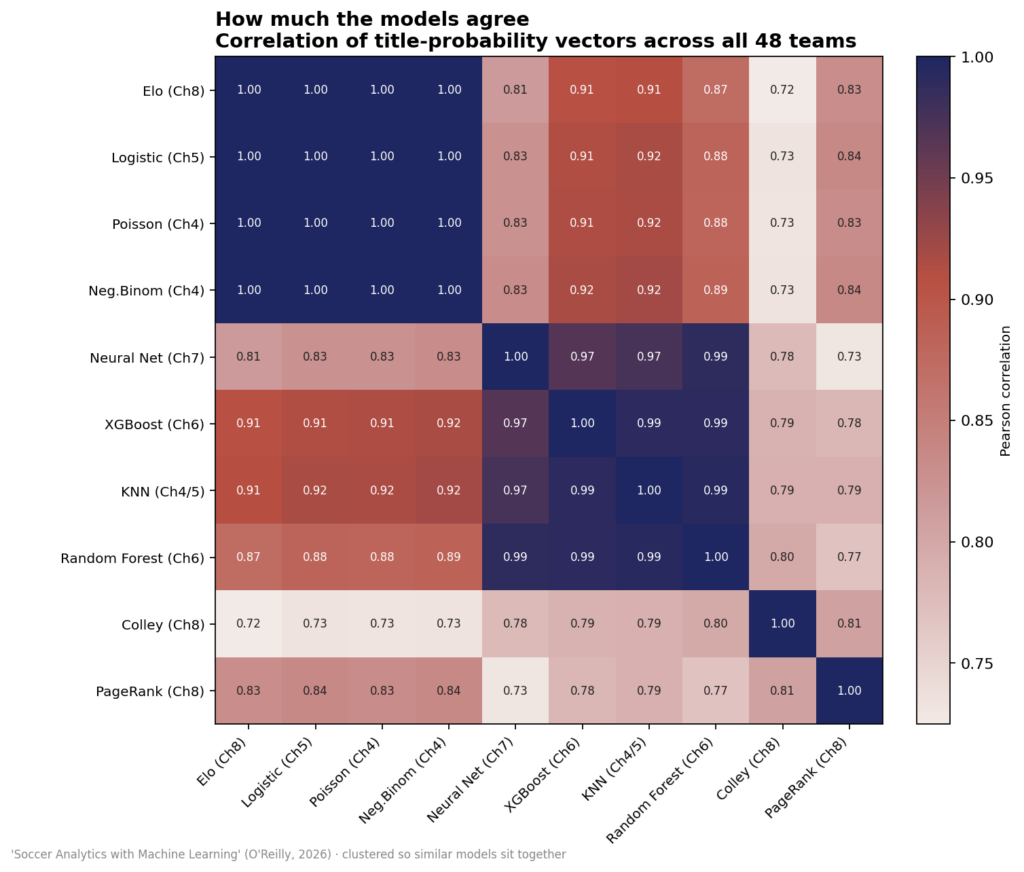 Bản đồ nhiệt sự đồng thuận giữa các mô hình
Bản đồ nhiệt sự đồng thuận giữa các mô hình
Tại sao chúng bất đồng — ba lý do thực sự
Có ba lý do riêng biệt cho sự bất đồng này, và không cái nào trong số đó liên quan nhiều đến bóng đá như vậy:
- Nguồn thông tin: Elo và tỷ lệ cược ngầm của thị trường mã hóa phong độ toàn cầu hiện tại; Colley và PageRank chỉ mã hóa kết quả trong tập dữ liệu. Khi kết quả gần đây của một đội vượt xa danh tiếng của họ (Hà Lan ở đây), các phương pháp đồ thị phân kỳ mạnh mẽ với các phương pháp dựa trên phong độ.
- Bàn thắng vs Kết quả: Họ Poisson mô hình hóa tỷ số và suy ra người thắng; các bộ phân loại mô hình hóa kết quả trực tiếp. Trong các trận đấu sát nút, hai tuyến đường này gán khối lượng hòa khác nhau và do đó khả năng sống sót ở vòng loại khác nhau.
- Thiên kiến (Bias) vs Phương sai (Variance): Các cây tăng cường bắt được các tương tác tinh tế hơn trong dữ liệu huấn luyện và nghiêng về Argentina; các mô hình tuyến tính làm mịn những thứ đó. Chỉ với 358 trận đấu, sự linh hoạt đó có khả năng fit nhiễu (overfitting) nhiều hơn là tín hiệu.
Đồng thuận và phạm vi ý kiến
Đồng thuận — trung bình mười mô hình phi thị trường — vẫn đọc hợp lý: Tây Ban Nha có xác suất thắng ~20%, Pháp và Argentina ~14%, sau đó là Hà Lan và Anh. Việc trung bình hóa các mô hình bản thân nó là một phương pháp: một ensemble đơn giản thường đánh bại hầu hết các thành viên của nó vì các lỗi không tương quan phần nào triệt tiêu lẫn nhau.
Nhưng hãy chú ý các thanh màu xám — phạm vi từ tối thiểu đến tối đa trên các mô hình. Chúng rất rộng. Bất kỳ ai đưa cho bạn một con số duy nhất cho "ai thắng World Cup" đang giấu đi những thanh đó, và những thanh đó mới là phần trung thực.
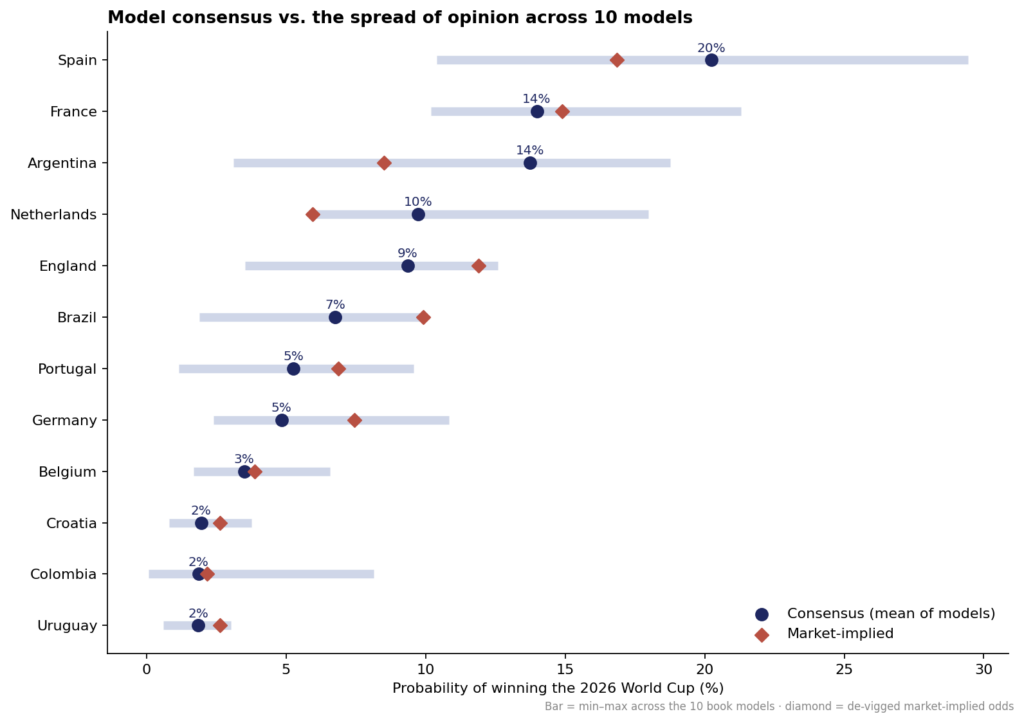 Đồng thuận so với phạm vi ý kiến của các mô hình
Đồng thuận so với phạm vi ý kiến của các mô hình
Bài học vượt ra ngoài bóng đá
Thiết lập này mở ra hai chủ đề đáng để kéo trên dữ liệu của riêng bạn. Thứ nhất, tỷ lệ cược ngầm của thị trường chỉ là một cột khác trong bản đồ nhiệt đó. Bước tiếp theo tự nhiên là xếp đồng thuận mô hình lên với xác suất đã loại bỏ phí của thị trường và hỏi xem chúng bất đồng ở đâu và tại sao.
Thứ hai, bạn có thể giả định rằng các mô hình linh hoạt hơn như XGBoost và mạng nơ-ron fit dữ liệu lịch sử tốt nhất. Các điểm số cross-validation nói ngược lại, và lý do là chúng ta đang overfitting trên một tập dữ liệu nhỏ và chiều thấp. Đó là một bài học đi xa hơn nhiều bóng đá.
Bài viết liên quan
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026

Công nghệ
Pinterest tích hợp Amazon Storefront, đặt cược lớn vào người sáng tạo
10 tháng 6, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng, ra mắt tính năng cá nhân hóa thuật toán mới
16 tháng 6, 2026